AdaBoost(에이다부스트, Adaptive Boosting)
유튜브 채널 StatQuest의 https://www.youtube.com/watch?v=LsK-xG1cLYA&t=0s 를 정리하였음
사전지식 : Decision Tree, Random Forest
AdaBoost를 밑바닥부터 살펴보자.
랜덤포레스트에서는, 매시각 트리를 만들면서 풀사이즈 트리를 만들었었다.
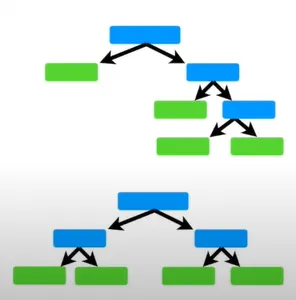
이 트리들은 서로 다르게 생겼겠지만, 모두 미리 정한 최대 깊이만큼 만들어졌다. AdaBoost에서는 이 트리들이 아래 그림처럼 하나의 노드와 두 개의 리프로만 만들어진다.
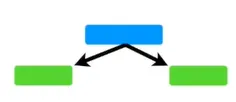
스텀프.
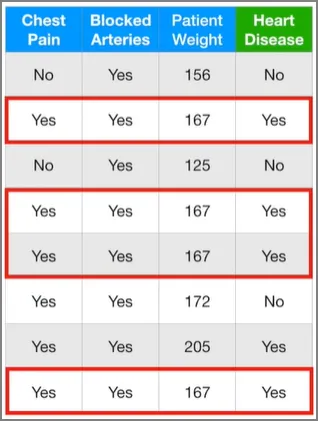
이걸 스텀프(Stump, 그루터기)라고 부르기로 하자. 그런데 이 스텀프들은 분류 성능이 안 좋을 것이다. 아래 데이터를 예로 들어보자.
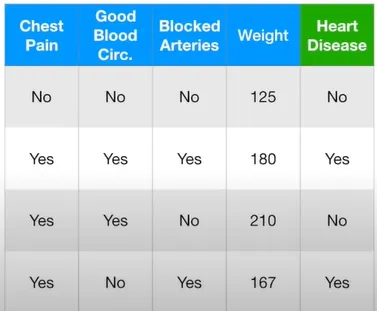
Decision Tree는 네 가지 변수를 모두 사용해서 심장병을 예측하겠지만, 스텀프는 오직 하나의 변수만 사용할 것이기 때문이다. 그러므로, 스텀프는 ‘약한 학습자(weak, learner)’이다. 하지만 Adaboost는 이 스텀프를 좋아하며, 바로 Adaboost가 널리 사용되는 이유이기도 하다.
랜덤포레스트를 다시 살펴보자. 랜덤 포레스트에서의 각 트리는 최종 분류에 있어 모두 동등한 영향력을 갖고 있었다. 그러나, Adaboost에서 만들어지는 스텀프들은 최종 결정에 있어서 일부가 더 큰 영향력을 발휘한다는 점이 다르다.
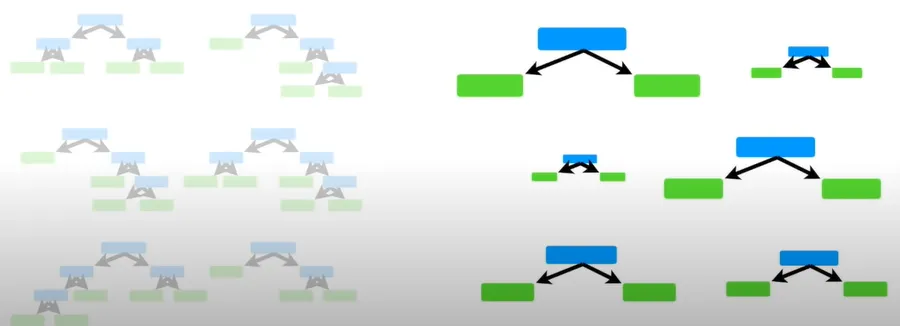 랜덤 포레스트에서는 모든 트리가 동일한 영향력을 발휘해 예측하지만, Adaboost에서는 모두 영향력이 다르다.
랜덤 포레스트에서는 모든 트리가 동일한 영향력을 발휘해 예측하지만, Adaboost에서는 모두 영향력이 다르다.
마지막으로, 랜덤포레스트에서는 각 Decision Tree가 독립적으로 만들어진다. 하지만 Adaboost의 스텀프들은 만들어지는 순서가 중요하다. 첫 번째 만들어진 스텀프의 에러는 두 번째로 만들어지는 스텀프에 영향을 끼친다. 그리고 두 번째로 만들어진 스텀프의 에러가 세 번째 만들어지는 스텀프에 영향을 끼친다. 이런 식으로 계속 만들어진다.
종합적으로 Adaboost의 핵심 세 가지 아이디어는 다음과 같다.
Adaboost는 “weak learner”들을 결합하여 분류에 사용하며, weak learner들은 거의 항상 스텀프의 형태이다. 일부의 스텀프가 다른 것들보다 분류에 있어 더 큰 영향력을 행사한다. 각 스텀프는 이전 스텀프의 실수를 고려해서 만들어진다. 이제 AdaBoost의 세부 과정을 살펴보자.
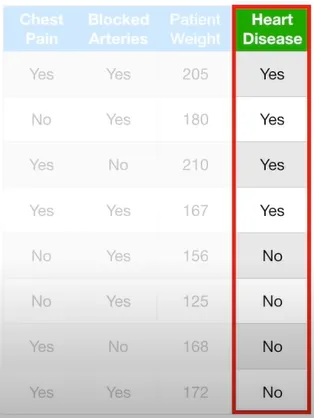
환자가 심장병을 앓는 사람인지 예측하기 위하여 AdaBoost에서의 스텀프들을 만들어보자. 가슴통증(Chest Pain), 동맥경화(Blocked Arteries), 몸무게(Patient Weight)를 예측에 이용하자.
첫 번째로 할 것은, weight(가중치)를 주는 것이다. 이 가중치는 해당 샘플이 올바른 분류에 얼마나 중요한 역할을 하는 지를 의미한다. 처음 시작할 때는 모두 동일한 가중치를 준다. 아직까지는 모든 샘플이 동일한 중요도를 갖는다.

하지만, 첫 번째 스텀프를 만들고 난 후부터 이 가중치들은 변화해갈 것이다.
자, 첫 번째 스텀프를 만들어보자. 가장 분류를 잘하는 변수를 고르면 된다. 아직은 가중치가 다 똑같기 때문에 지금은 가중치를 무시해도 된다.
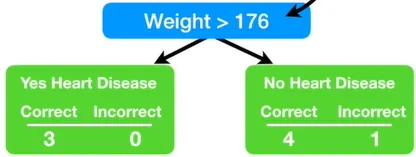
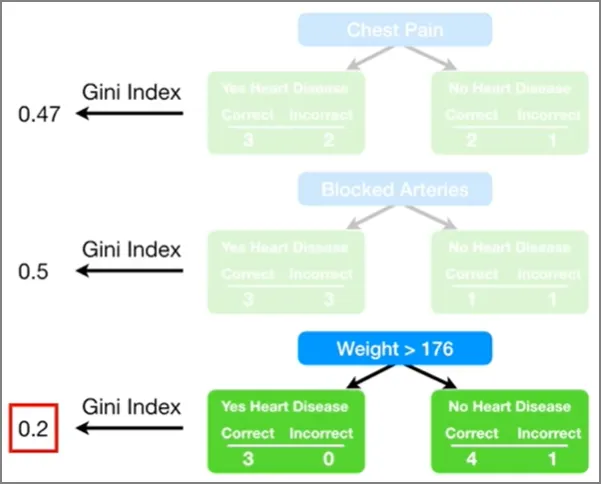
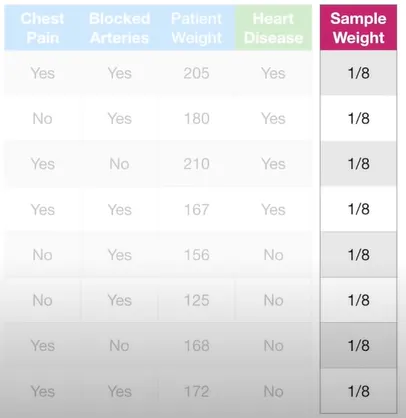
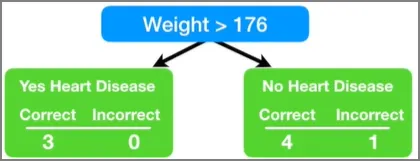
Weight 변수로 나눴을 때 지니인덱스가 가장 낮다. 그렇기 때문에 Weight 변수가 첫 번째 스텀프에 사용된다. 이제 이 스텀프가 최종 예측에 얼마나 영향력을 행사하면 될 지에 대해 알아보자.
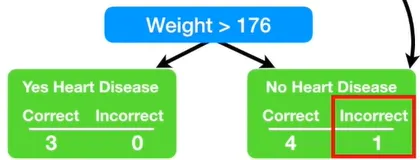
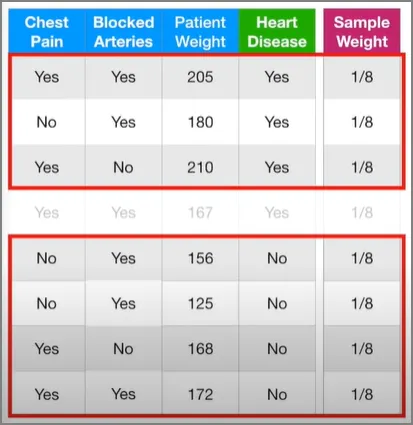
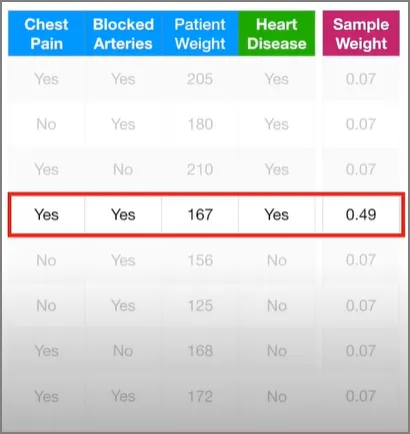
이 스텀프는 Weight 변수가 176보다 크면 심장병을 가지고, 그게 아니면 심장병을 안 갖고 있다고 예측했다. 이 스텀프는 1개 샘플 만큼의 에러를 갖고 있다. 즉, 저 몸무게 167의 환자는 176보다 작은데 심장병을 갖고 있어서, 첫 번째 스텀프 관점에서는 에러에 해당한다.

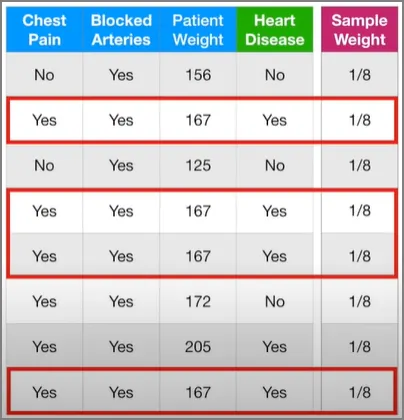
한 스텀프에 대한 Total Error(총 에러)를 잘못 분류된 샘플들의 가중치를 모두 더한 것이라고 정의하자. 그러므로 이 경우에는 총 에러가 1/8이다.
*주의 : 샘플 가중치는 모두 더하면 1이다. 그러므로 가장 잘 분류했을 때 0, 가장 못 분류했을 때 1로 0에서 1사이의 값이다.
우리는 이 총 에러를 가지고 이 스텀프가 최종 예측에 얼마만큼의 영향력을 행사하면 좋을지를 판단하면 될 것이다. 에러를 가지고 스텀프의 영향력을 계산할 때, 다음과 같은 식을 사용하기로 하자.
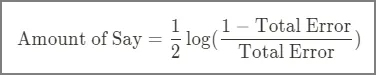
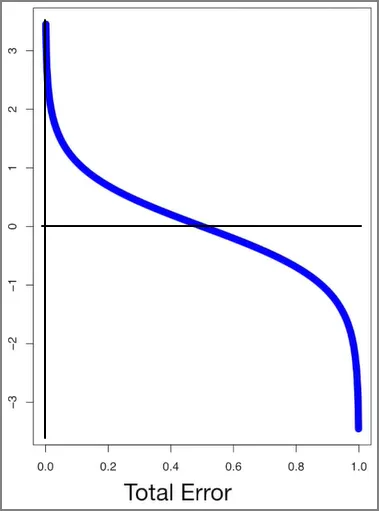
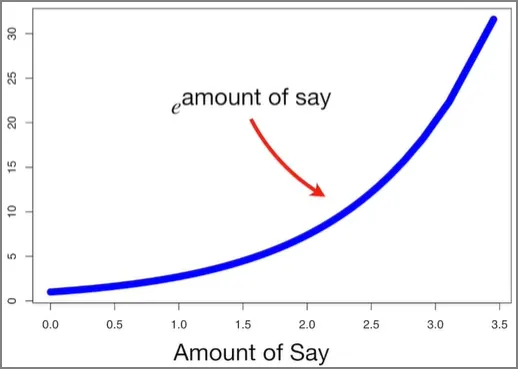
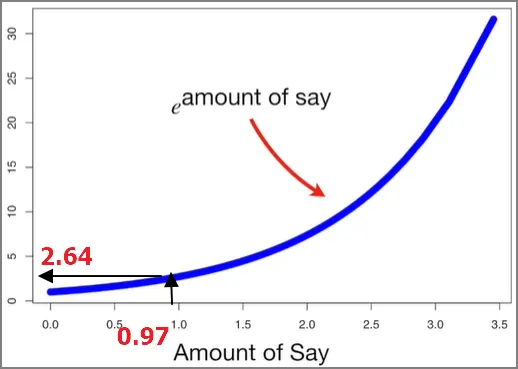
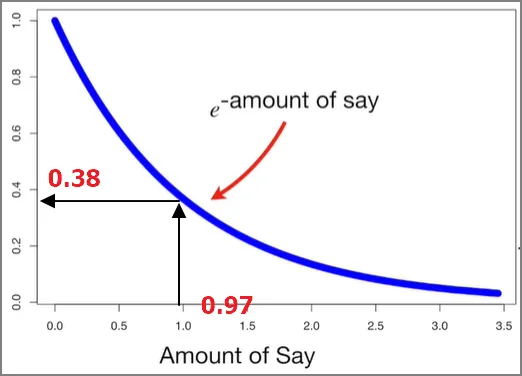
총에러가 0에서 1사이이기 때문에 그래프를 그려보면 위와 같다. Y축은 Amount of Say이다. 스텀프가 분류를 잘 했다면, 총 에러는 작고, 영향력은 커질 것이다. 반대로 스텀프가 분류를 못했다면, 총 에러는 1에 가까워지고, 영향력은 마이너스가 될 것이다.
총 에러가 커지는 경우는 무엇일까? 만약 스텀프의 분류 결과가 동전뒤집기보다 확률이 안좋다면, 즉 샘플의 절반이 잘 분류되고 절반은 잘못 분류되었다면, 총 에러는 잘못 분류된 샘플들의 가중치 합이니까 0.5일 것이다. 그럼 영향력은 0이 된다.
그리고 총 에러가 1에 가까워지는 최악의 상황에서는, 즉, 스텀프가 반대로 분류한다면, 이 스텀프의 영향력은 큰 음수가 될 것이다. 그래서 만약에 최종 투표에 가서 어떤 스텀프가 심장병에 대해서 투표를 할 때, 음의 영향력을 가진 스텀프가 ‘심장병 맞음’으로 투표한 것은 “심장병이 아님” 쪽으로 투표하는 것과 마찬가지가 되도록 하는 것이다.
주의 : 만약 총 에러가 1 또는 0이면, 위 영향력 수식은 발산하는데, 실제로는 작은 에러 항이 이러한 발산을 막기 위해 더해지므로 걱정안해도 된다.
자 다시 데이터로 돌아와서, Weight 변수로 만든 스텀프의 총 에러는 1/8이고, 이 스텀프의 영향력은 0.97이 된다.
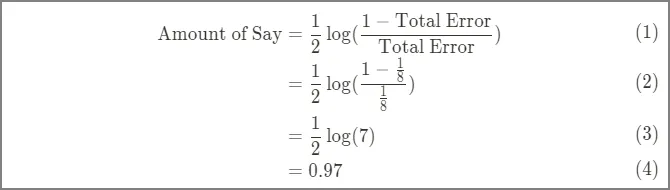
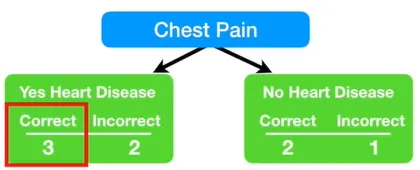
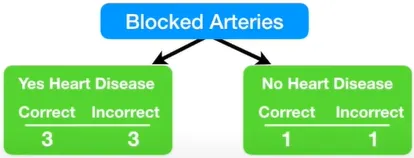
스텀프의 영향력을 모두 계산해 봤으니까, Blocked Arteries 변수의 스텀프가 가장 좋은 스텀프였다면 어땠을지 영향력을 한번 계산해보자. 이것은 이 데이터에서는 발생하지 않았을 일이지만, 지금까지 했던 과정을 이해하는데에 도움이 된다.
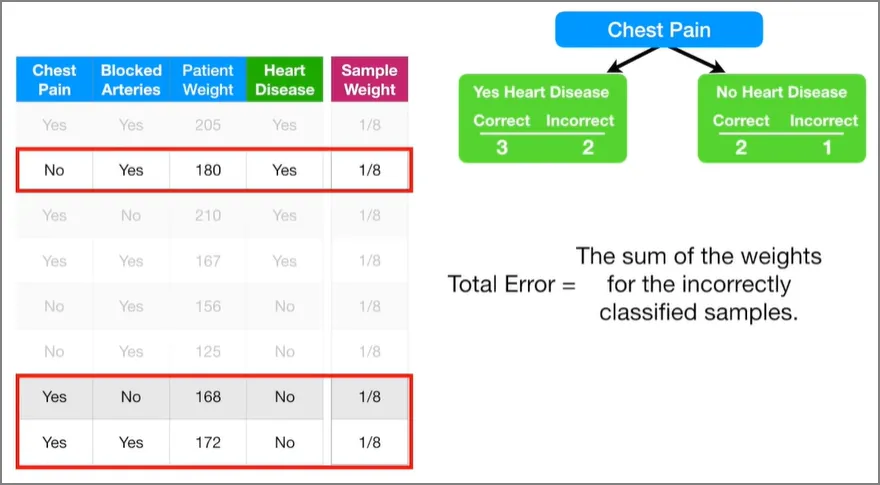
총 에러는 잘못 분류된 샘플들의 가중치 합이다.
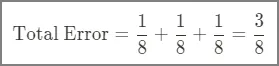
Blocked Arteries 변수로 스텀프를 만들었을 때 총 에러는 3/8이다. 이걸로 스텀프의 영향력을 계산해보면 0.42가 나온다.
자, 이제 우리는 틀리게 분류된 샘플들의 가중치들로 각 스텀프의 영향력을 어떻게 계산할 수 있는지를 알게되었다. 이제는 이전 스텀프의 에러가 현재 스텀프를 만들때 어떻게 고려되는지 배워보자.
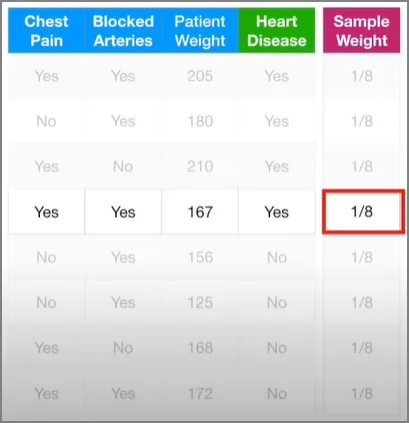
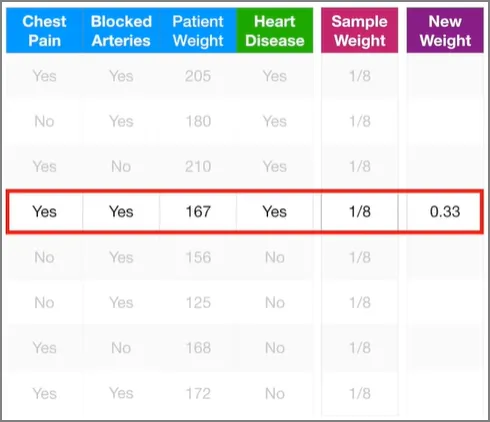
다시 첫 번째 스텀프로 돌아가서 시작하자. 우리가 첫 번째 스텀프를 만들었을 땐 샘플 가중치가 모두 똑같았다. 즉, 예측에 있어서의 각 샘플의 중요도를 아직까지는 강조해주지 않았다는 것이다. 그러나 이 스텀프가 키 167인 사람 샘플을 잘못 분류했기 때문에, 우리는 다음 스텀프가 이 샘플의 가중치를 더 증가시켜서, 다음 스텀프를 만들 때는 이 샘플까지 잘 분류하도록 만들 필요가 있다. 마찬가지로, 잘 분류된 다른 샘플들의 가중치는 감소시켜도 된다. 자, 그럼 잘못 분류된 저 샘플의 가중치를 증가시켜보자.

잘못 분류된 샘플의 가중치를 증가시키기 위하여, 우리는 위와 같은 공식을 사용한다. Sample weight에는 마지막 스텀프에서 사용했던 가중치를 넣어준다. 그리고 exponential 항으로 이 가중치를 늘이고, 줄이게 된다.
마지막 스텀프가 분류를 잘 했을때, 즉, 영향력이 클 때, 그 샘플의 가중치에는 큰 숫자가 곱해진다. 이렇게 기존 샘플 가중치가 많이 더 증가하게 된다. 반대로 영향력이 작을 경우, 즉 마지막 스텀프가 분류를 잘 못했으면, 샘플 가중치에는 상대적으로 작은 숫자가 곱해지게 된다. 즉, 이 샘플의 가중치는 증가하게 된다. 이 예시에서는, 마지막 스텀프의 영향력은 0.97이었고,
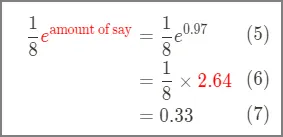
새로운 샘플 가중치는 0.33이므로, 이 샘플의 기존 가중치인1/8=0.125보다 커진 것을 알 수 있다
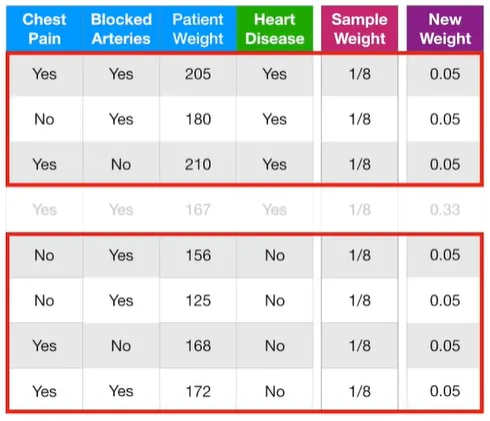
자, 이제 잘 분류된 샘플들은 상대적으로 가중치가 줄어들어야하겠다. 이제 이 샘플들의 가중치를 줄여보자.

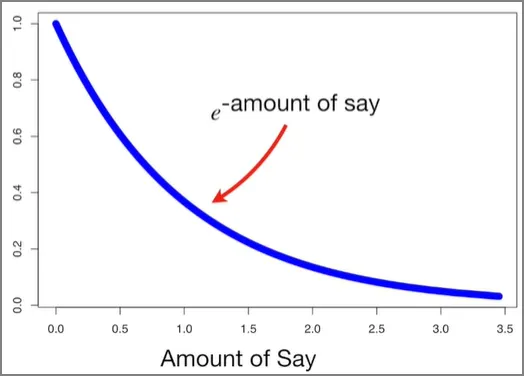
위 공식으로 잘 분류된 샘플들의 가중치를 줄여준다. 잘 분류된 샘플들과의 차이점은 영향력 앞에 -가 붙었다는 것이다. 영향력이 큰 스텀프의 경우, 잘 분류된 샘플들의 가중치에는 0에 가까운 숫자가 곱해진다. 이로 인해 가중치가 매우 작아지게 된다. 만약 영향력이 작은 스텀프의 경우에는, 잘 분류된 샘플들의 가중치에는 1에 가까운 숫자가 곱해진다. 이로 인해 이 샘플들의 가중치는 상대적으로 덜 작아지게 된다.
이 예시에서는, 마지막 스텀프의 영향력이 0.97이었기 때문에,
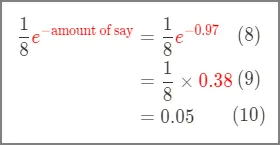
이렇게 이 샘플들의 새로운 가중치는 0.05가 되어, 기존의 가중치 1/8=0.125보다 작아지게 되었다. 위 수식을 잠시 들여다보면, 이전 스텀프의 영향력이 꽤 큰 편이었기 때문에(좋은 분류기였기 때문에), 잘 분류된 샘플들에 대해서는 가중치가 좀 많이 낮아진 것이다. 스텀프의 말을 잘 들어야지!
새로운 샘플 가중치에 대해서 다시 기록해보자. 첫 스텀프에 의하여 잘못 분류된 샘플, 즉, 키 167인 사람의 샘플은 0.33이 되었고, 잘 분류된 사람들은 0.05가 되었다.
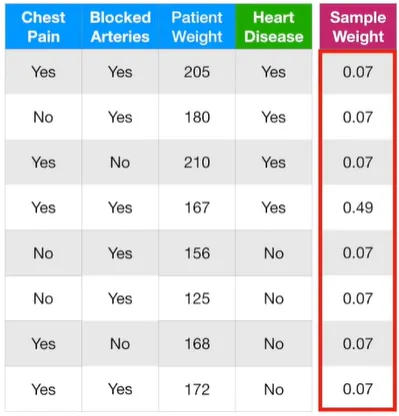
이 샘플 가중치들을, 더하면 1이 되도록 노멀라이징하자. 지금 샘플 가중치를 모두 더하면 0.68이기 때문에, 각 샘플 가중치들을 0.68로 나눠주자. 자, 우리는 이제 전체 합이 1인 새로운 샘플 가중치를 얻게 되었다. 휴 힘들었다.
그 다음부터는 여러가지 전략을 취할 수 있다.
그 중 한가지로, 이론상, 우리는 다음 스텀프를 만들 때 샘플 가중치를 이용해서 가중 지니계수를 계산할 수 있다.
위의 167인 사람의 샘플이 이전 스텀프에서 잘못 분류되어 가장 큰 샘플 가중치를 가지게 되었기 때문에, 가중 지니계수는 이 샘플을 더 옳게 분류하는데에 더 집중하게 될 것이다. 아니면 대안적으로는, 가중 지니계수를 사용하는 것 대신에, 우리는 이러한 큰 샘플가중치를 갖는 샘플들을 복사해서 이들을 포함하는 새로운 샘플 집합을 만들 수도 있다. 자, 그럼 원본 데이터와 같은 크기의 아무것도 없는 새로운 데이터셋으로부터 시작해보자.

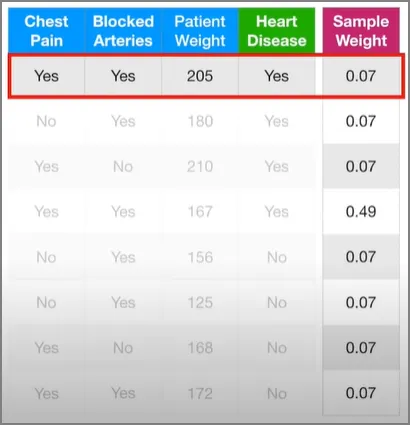
0\~1 사이의 랜덤 숫자를 하나 만들자. 만약 그 숫자가 0\~0.07이면 첫 번째 데이터를, 0.07\~0.14이면 두 번째 데이터를 새로운 데이터에 추가시키는 방식으로 해보자. 예를 들어, 첫 번째 랜덤 숫자가 0.72가 나왔다면,
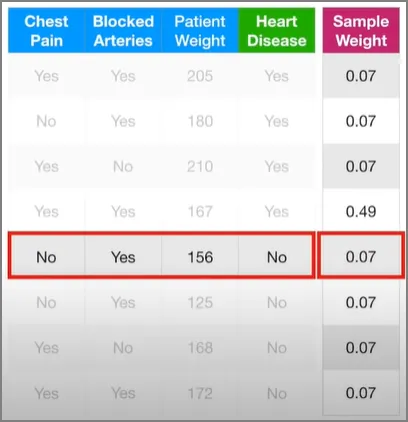
이 데이터를 새로운 데이터셋에 추가하는 것이다. 이런 식으로 해서 만들어진 데이터가 가장 오른쪽 처럼 된다고 하면, 이 데이터는 샘플 가중치에 의존하여 하나의 샘플을 무려 네 번을 갖는, 원본 데이터셋과 같은 크기의 새로운 데이터셋이 될 것이다. 이제 이 새로운 데이터셋을 이용하자.
자, 전에 했던 것처럼 새로운 데이터셋에 모두 같은 샘플 가중치를 주자. 그런데, 이는 다음 스텀프가 167인 사람을 잘 분류하기 위해 만들어진다는 의미는 아니다. 이 샘플들은 모두 같은 샘플이기 때문에, 이들은 block(?)으로서 취급 될 것이며, 잘못 분류되는 것에 대해 큰 페널티를 만들 것이다.
자, 이전에 잘못 분류되었던 샘플들이 더 많아졌다. 다시 처음으로 돌아가서 이 데이터셋에 대해서 가장 잘 분류하는 스텀프를 만들어보자.
잘못 분류된 샘플들이 많아진 데이터셋이다. 이걸로 모델을 만들면 더 힘든(?) 샘플들까지 분류하려는 스텀프가 만들어질거고, 이것들까지 분류를 잘하면 이 스텀프의 영향력도 세질것이다.
이런 식이 바로 첫 번째 트리(스텀프)의 에러가 두 번째 트리에 영향을 미치고, 두 번째 트리의 에러가 세 번째 트리에 영향을 미치는 방식이다.
자, 이제 스텀프들의 집합이 새로운 샘플에 대해 어떻게 최종 분류를 하는지에 대해 알아보자.
왼쪽 스텀프들이 어떤 새로운 샘플을 심장병이 있는 사람으로 분류했고, 오른쪽에 있는 스텀프들이 이 샘플을 심장병이 없는 사람으로 분류했다고 하자.
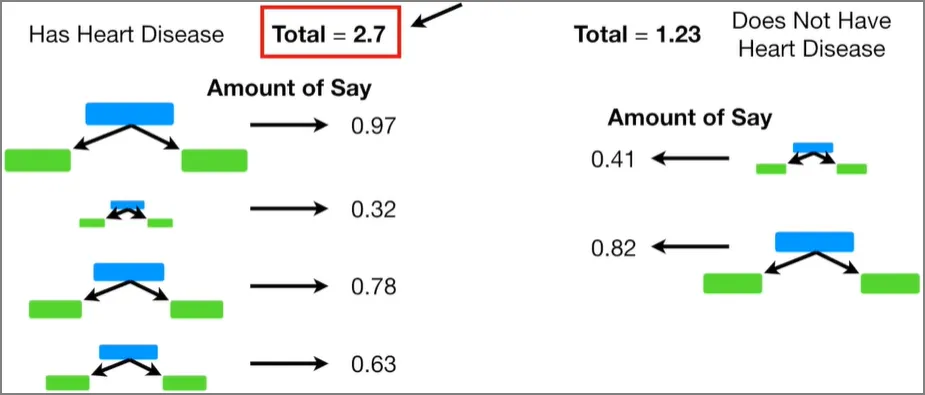
각 진영에 있는 스텀프들의 영향력을 다 더해보자. 그럼 심장병이 있다고 예측한 스텀프들의 영향력 합이 더 높다. 그럼 결과적으로, 이 샘플은 영향력이 더 큰 쪽으로, 즉 심장병이 있다고 분류하게 된다.
끝났다. AdaBoost의 세 가지 아이디어를 다시 리뷰해보자.
AdaBoost는 다수의 약한학습자를 결합해서 분류 결과를 내놓는다. 약한 학습자는 거의 모든 경우 스텀프이다. 일부 스텀프는 다른 스텀프들보다 영향력이 세다. 즉, 스텀프의 영향력에는 차등이 존재한다. 각 스텀프는 이전 스텀프의 에러를 고려하여 만들어진다. 그 다음 스텀프를 만들 때는 가중 지니계수를 사용할 수도 있고, 아니면 샘플 가중치를 그대로 사용해서 새로운 데이터셋을 만들어서 반영할 수도 있다. AdaBoost는 Adaptive Boosting의 줄임말로, 아다부스트가 아니라 에이다부스트라고 발음하는 것이 맞다(위키피디아에서 그런다). 뒤의 약한 학습기가 계속 잘못 분류된 것들을 수정해준다고 해서 adaptive가 붙었다. 그래서 AdaBoost는 이상치에 로버스트하지 못하다.
끝!!!!!!!!!!!!