[kdd cup tencent] InterFormer: Effective Heterogeneous Interaction Learning for Click-Through Rate Prediction
![[kdd cup tencent] InterFormer: Effective Heterogeneous Interaction Learning for Click-Through Rate Prediction](https://posting-files.s3.ap-northeast-2.amazonaws.com/uploads/051b3c1f-6892-4669-9d26-0defd4e291ed.jpg)
CTR 예측은 추천시스템에서 가장 기본적인 태스크임!
이질적인 정보가 등장했다. Heterogeneous information.
즉, 유저 프로필과 행동 시퀀스같은 것인데, 각각은 유저의 선호도/흥미를 다른 방식으로 바라본 데이터다.
이 둘은 서로서로 도움이 되는 방식으로 합쳐질 필요가 있는데, 이게 CTR 예측에 성공하기 위한 초석이다.
하지만, 기존의 방법들은 두가지 한계에 부딪혀 왔음:
-
inter-mode 인터랙션이 충분하지 않다.
mode가 뭐냐?
CTR 예측에서 feature는 보통 두 종류로 나뉜다.- Sequential mode : 사용자 행동 시퀀스. 최근 본 아이템들, 클릭 히스토리 등.
- Non-sequential mode : 일반 피쳐. 즉, 유저 나이나 아이템 카테고리나 지역 등
그니까, inter-mode 인터랙션이 충분하지 않다.는 말은, 두 종류의 feature가 서로 영향을 주고받지 못하고, 한쪽이 다른 쪽으로만 흐른다 :
단방향 (기존 방식):
S → N
이때 N은 S의 처리 과정에 영향을 못 줘요. 시퀀스는 N이 뭐든 상관없이 자기 혼자 알아서 인코딩됨.
양방향 (InterFormer가 주장):S ⇄ N
Sequential를 인코딩할 때 Non-sequential의 정보를 참고하고, N을 처리할 때도 S의 정보를 참고. 서로 왔다갔다.
2. 공격적으로 정보를 집계한다.
정보 집계? 시퀀셜 추천에서는 보통 임베딩을 sum, mean, [cls]토큰 등으로 N개의 아이템 임베딩을 1개의 벡터로 aggregation한다. 그래서 이 때 정보의 손실이 발생한다는 뜻.
정리하면 두 한계가 사실 연결돼 있어요:
- 단방향 흐름 = 시퀀스가 컨텍스트 없이 혼자 처리됨
- early aggregation = 그 처리가 "한 방에 뭉개기"라서 정보 손실까지 큼
그래서 Interformer라는 새로운 모듈을 만들었음. 이는 이질적인 정보 인터랙션을 interleaving 방식으로 학습한다.
Introduction
CTR 예측에 있어서 유저의 흥미를 잘 캐치하는게 매우 중요한데, 이질적인 정보들이 등장했음.
즉, Non-sequence 피쳐들(유저 프로필, 맥락)은 정적인 관점을 알 수 있고, 행동 시퀀스는 유저의 흥미가 동적으로 변화한다는 점을 알 수 있지.
대부분의 기존 CTR 예측 모델들은 두가지 카테고리로 묶을 수 있음: non-sequential, sequential 모델.
non-sequential 몯ㄹ은 피쳐 인터랙션을 내적, MLP, 딥러닝 구조의 모델에서 임베딩을 잘 학습하는것에 초점이 맞춰져있음. 하지만 시퀀셜 정보는 무시한다.
반대로 Sequential 모델은 CNN이나 RNN, Attention같은 것을 추가적으로 더 사용한다. 그래서 유저 행동 속에서 sequential한 정보를 얻기위해 노력한다.
유망해 보이긴 하지만, 기존의 시퀀셜 방법들은 대부분 단방향 정보 흐름을 사용한다. 즉, 비시퀀셜 정보가 시퀀스 학습을 가이드하는 데는 쓰이지만, 그 반대 방향 — 시퀀스에서 비시퀀스로 가는 정보 흐름은 대부분 무시되어 왔음.
무슨말이냐? 후보 아이템의 Non-sequential 정보를 사용해서, “유저 시퀀스 중에서 attention을 걸어서, 이 후보 아이템과 관련된 히스토리에 더 집중”하는 방식을 썼다는 뜻. 즉, Non-sequential → sequential은 사용되어왔음.
무시되어온 것은: sequential → non-sequential임.
예를 들어, non-sequential 정보는 장기적 관심사(long-term interests)를 포착하는 반면에, sequential 정보는 순간적 관심사(momentary interests)를 나타낸다.
즉, 두 정보가 포착하는 시간 스케일이 다르다 :
- non-sequential → 장기적 관심사.
- 유저의 안정적이고 지속적인 속성.
- 나이, 성별, 지역, 직업, 산업
- 잘 안변함. 본질적.
- sequential → 순간적 관심사
- 최근 1시간동안 본 아이템들
- 오늘 검색한 키워드
- 빨리 변함. 지금 이 순간의 의도/맥락을 보여줌.
- 개발자인데 → 캠핑에 꽂힘
이런 순간적인 관심사는, 비시퀀셜 컨텍스트를 더 풍부하게 만들어줄 수 있다는 것임.
계산 비용은?
인터랙션 학습을 제대로 하려면, 모든 N개의 non-sequential 피쳐와 sequential length를 고려한다고 하면 현실적으로:
- Non-sequential features: 수십\~수백 개 (유저 feature, 아이템 feature, 컨텍스트 feature 다 합치면)
- Sequential length: 수십\~수백 개의 과거 행동 (보통 50\~200개, 길면 1000개 이상)
이 둘을 다 연산하려며니, 연산 폭발함. 추천시스템은 실시간 서빙이 생명임(수십 ms안에 응답해야함).
그러다보니 시퀀스를 일찍이 압축해버리는 방법을 사용하는데, 이렇게하면 디테일한 정보는 날아가게됨.
→ 그래서 우리는 계산 효율성도 챙기면서 fine-grained로 가겠다.
fine-grained란??
예시로 보죠. 유저 시퀀스가:
[등산화, 캠핑의자, 노트북, 키보드, 텐트]
그리고 후보 아이템(N) = "헤드램프"
Coarse-grained:
- 시퀀스 5개를 평균내면 → "아웃도어 + 전자제품" 짬뽕된 모호한 벡터
- 헤드램프와의 관련성 → 약하게 잡힘
Fine-grained:
- 등산화 ↔ 헤드램프 → 강한 관련성
- 캠핑의자 ↔ 헤드램프 → 강한 관련성
- 노트북 ↔ 헤드램프 → 약한 관련성
- 키보드 ↔ 헤드램프 → 약한 관련성
- 텐트 ↔ 헤드램프 → 강한 관련성
- → "아 이 유저는 캠핑/등산 모드구나, 헤드램프 매우 관련 있음"
3. Preliminaries
추후 업데이트
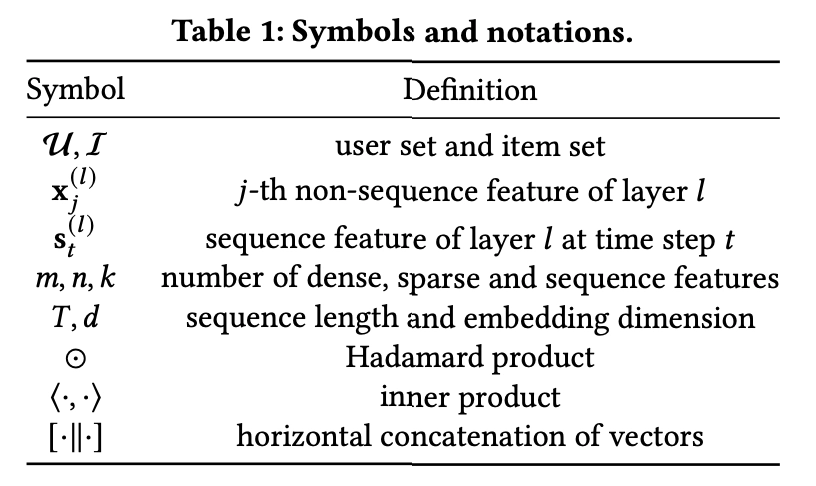
4. Methodology
4.1 Feature Preprocessing
Non-Sequence Feature Preprocessing.
두 가지 타입의 non-sequence 피쳐를 다룸
- dense feature : 유저 나이, 아이템 가격 등
- sparse features : 유저 id, 아이템 category 등
non-sequential 피쳐의 이질성을 통일시키기 위해, 서로 다른 피쳐들을 모두 같은 차원의 임베딩으로 변환함
모든 feature를 같은 차원의 벡터로 통일한다.
dense feature들을 어떻게 d차원 벡터로 만드는지 수식으로 설명:
예를 들어 m개의 dense feature가 있다고 하자.
유저 나이 : 28 유저 활동일수 : 156 아이템 가격 : 199 평균 CTR : 0.034
이 원시(raw) dense feature들 $ $들을 concat해서 m차원 벡터로 만든다.
$들을 concat해서 m차원 벡터로 만든다.
$x^{(0)}_{\text{dense}} = [28, 156, 199, 0.034]^{T}$
(0)은 레이어를 의미함 → $x^{(l)}_{j}$ : l번째 레이어의 j번째 non-sequence feature.
레이어란,
$$ x⁽ˡ⁾ = "l번 변환을 거친 후의 representation" $$