추천시스템에서의 Multi-Armed Bandit-1

Introduction
추천시스템을 운영하다 보면 근본적인 딜레마에 직면한다. 이미 잘 되는 걸 계속 추천할 것인가(Exploitation), 아직 모르는 새로운 아이템을 시도해볼 것인가(Exploration). 이 문제를 체계적으로 다루는 프레임워크가 바로 Multi-Armed Bandit(MAB)이다.
슬롯머신(one-armed bandit)이 여러 대 있을 때, 어떤 머신의 레버를 당겨야 총 보상을 최대화할 수 있는가? 이것이 MAB 문제의 핵심이다.
구체적인 예시: 넷플릭스 홈 화면
넷플릭스에 처음 가입한 유저가 있다고 하자. 이 유저의 취향을 아직 아무것도 모른다. 홈 화면에 어떤 콘텐츠를 보여줘야 할까?
전략 1: 인기순 추천 (Pure Exploitation)
모든 신규 유저에게 전체 인기 Top 10만 보여준다. 평균적으로 나쁘지 않겠지만, 한국 드라마만 좋아하는 유저에게 미국 시트콤을 계속 밀어넣는 셈이다. 이 유저가 한국 드라마를 좋아한다는 걸 영원히 알 수 없다.
전략 2: 완전 랜덤 추천 (Pure Exploration)
매번 완전히 랜덤으로 콘텐츠를 보여준다. 유저 취향을 빠르게 파악할 수 있겠지만, 대부분의 추천이 엉뚱해서 유저가 이탈할 것이다.
전략 3: Multi-Armed Bandit
처음에는 다양한 장르를 골고루 보여주되(exploration), 유저가 클릭한 장르의 비중을 점점 높여간다(exploitation). 한국 드라마를 3번 클릭했다면 한국 드라마 비중을 올리되, 가끔 다큐멘터리나 애니메이션도 슬쩍 끼워넣어 새로운 취향을 발견할 여지를 남긴다.
이것이 MAB의 핵심 아이디어다. 아는 것을 활용하면서도, 모르는 것을 탐색하는 균형을 수학적으로 최적화하는 것.
피드 시스템에서의 MAB
MAB는 cold start 상황만을 위한 도구가 아니다. 실시간으로 변하는 유저 관심사를 빠르게 추적해야 하는 모든 상황에서 유효하다. 실제로 여러 기업이 피드 랭킹에 MAB를 핵심 컴포넌트로 활용하고 있다.
Spotify 홈 피드: Spotify는 홈 화면의 플레이리스트 추천에 contextual bandit을 직접 적용한다. 어떤 플레이리스트를 어떤 순서로 보여줄지, 캐러셀(가로 스크롤) 안에서 어떤 항목을 앞에 배치할지를 bandit으로 결정한다. "Explore, Exploit, and Explain"이라는 이름의 시스템(BaRT)은 추천의 탐색-활용 균형을 잡으면서도 유저에게 "왜 이 추천을 했는지" 설명까지 제공한다. (Explore, Exploit, Explain — Spotify Research, RecSys 2018 | Homepage Personalization at Spotify, RecSys 2019 | Carousel Personalization with Contextual Bandits, RecSys 2020)
LinkedIn 피드: LinkedIn의 대규모 랭킹 시스템 LiRank는 피드 랭킹에 Neural Linear 기반의 explore/exploit 알고리즘을 적용한다. 다양한 콘텐츠 유형 중 어떤 것을 상단에 노출할지 결정할 때, 익숙한 콘텐츠만 밀어주는 대신 불확실성이 높은 새로운 콘텐츠에도 기회를 부여하는 방식이다. 실제로 engaged DAU(Daily Active Users)가 +0.17% 상승하는 효과를 확인했다. (LiRank: Industrial Large Scale Ranking Models at LinkedIn, KDD 2024)
YouTube 홈 피드: Google은 YouTube에 실시간 bandit 시스템 "Online Matching"을 적용하여 신규 콘텐츠 발견(fresh content discovery)과 아이템 탐색(item exploration)을 개선했다. Diag-LinUCB라는 LinUCB의 확장 알고리즘을 제안하여, 대규모 트래픽 환경에서도 bandit 파라미터를 실시간으로 업데이트할 수 있도록 했다. (Online Matching: A Real-time Bandit System for Large-scale Recommendations, RecSys 2023)
핵심은 이렇다: MAB는 "무엇을 추천할지"가 아니라 "어떤 전략으로 추천할지"를 결정하는 메타 레벨의 도구로 쓰인다.
용어부터 정리하자
Problem Formulation에 들어가기 전에, 앞으로 계속 나올 용어들을 직관적으로 이해하고 넘어가자.
Arm (팔)
슬롯머신의 레버를 당기는 팔에서 유래했다. 카지노에 슬롯머신이 5대 있으면 arm이 5개인 것이다. 추천시스템에서는 선택할 수 있는 각각의 옵션이 arm이 된다.
- 넷플릭스: 홈 화면에 보여줄 수 있는 각 장르 = arm
- 쇼핑몰: 추천 영역에 노출할 수 있는 각 상품 = arm
- 뉴스: 배치할 수 있는 각 기사 = arm
"Multi-Armed"라는 이름은 말 그대로 팔(선택지)이 여러 개라는 뜻이다.
하지만 상품 하나하나가 다 arm인 건 아니다
쇼핑몰에 상품이 수백만 개 있다고 arm이 수백만 개가 되면, 각 arm을 최소한 몇 번은 시도해봐야 하는데 탐색만 하다가 끝난다. 그래서 실무에서는 arm을 개별 아이템이 아니라 "추천 전략" 단위로 잡는다:arm_0 = "인기 상품 추천"arm_1 = "신상품 추천"arm_2 = "같은 카테고리 상품 추천"arm_3 = "함께 구매한 상품 추천"
이렇게 하면 arm이 3\~4개로 줄고, MAB는 "이 유저에게는 어떤 추천 전략이 가장 잘 먹히는가?"를 학습하는 것이 된다. 각 전략 안에서는 CF, MF, DNN 같은 각각의 추천 알고리즘이 돌아가고, MAB는 그 위에서 어떤 알고리즘의 결과를 노출할지 결정하는 메타 레벨의 의사결정자 역할을 한다.
실제 사례:Netflix: 홈 화면의 각 행(row)이 arm이다. "Because You Watched", "Top Picks", "Trending Now" 같은 추천 전략들 중 어떤 행을 상단에 배치할지를 bandit으로 결정한다. (A Multi-Armed Bandit Framework for Recommendations at Netflix)Spotify: 홈 화면의 각 선반(shelf)이 arm이다. "Made for You", "Recently Played", "New Releases" 같은 선반들을 어떤 순서로 보여줄지를 BaRT(Bandits for Recommendations as Treatments) 시스템이 결정한다. (Homepage Personalization at Spotify, RecSys 2019) 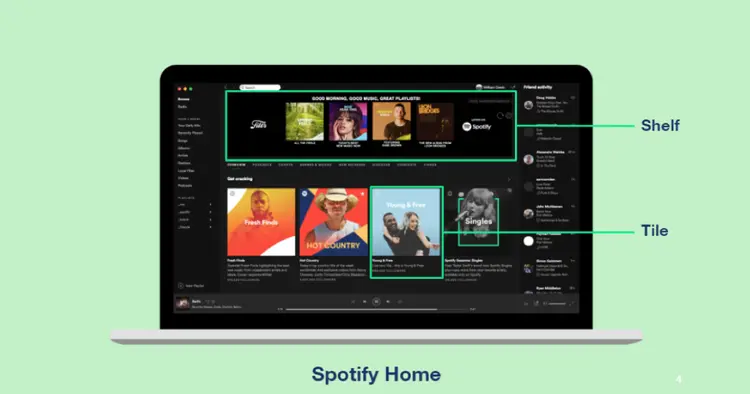 학술 연구: 여러 추천 알고리즘(CF, MF, DNN 등)을 각각 arm으로 놓고, MAB로 상황에 따라 가장 적합한 알고리즘을 선택하는 "bandit ensemble" 접근도 연구되고 있다. (Multi-armed Recommender System Bandit Ensembles, RecSys 2019)
학술 연구: 여러 추천 알고리즘(CF, MF, DNN 등)을 각각 arm으로 놓고, MAB로 상황에 따라 가장 적합한 알고리즘을 선택하는 "bandit ensemble" 접근도 연구되고 있다. (Multi-armed Recommender System Bandit Ensembles, RecSys 2019)
보상 (Reward)
arm을 하나 선택했을 때 돌아오는 결과다. 슬롯머신이면 동전이 나오거나 안 나오거나. 추천시스템이면:
- 유저가 클릭했다 → 보상 1
- 유저가 무시했다 → 보상 0
이렇게 단순하게 생각하면 된다. 보상은 꼭 0 또는 1일 필요는 없다. 예를 들어 슬롯머신에서 동전 500원이 나왔으면 보상 = 500, 유저가 추천 영상을 30분 시청했으면 보상 = 30이 될 수도 있다. 즉 보상이란, 내가 어떤 선택을 했을 때 돌아온 결과를 숫자로 매긴 것이다.
보상 분포 (Reward Distribution)
같은 슬롯머신을 여러 번 당겨도 매번 결과가 다르다. 어떤 때는 동전이 나오고, 어떤 때는 안 나온다. 하지만 그 머신만의 평균적인 경향은 있다. 1번 머신은 10번 중 3번 동전이 나오고, 2번 머신은 10번 중 7번 나오는 식이다.
이 "평균적인 경향"을 수학적으로 표현한 것이 보상 분포다. 우리는 이 분포를 모른다. 모르기 때문에 직접 당겨보면서 알아내야 한다. 이것이 MAB 문제의 핵심이다.
라운드 (Round)
선택을 하는 한 번의 기회다. 매 라운드마다 arm 하나를 골라야 하고, 고른 arm에서 보상을 받는다.
- 1라운드: 2번 머신 선택 → 동전 나옴 (보상 1)
- 2라운드: 2번 머신 선택 → 동전 안 나옴 (보상 0)
- 3라운드: 4번 머신 선택 → 동전 나옴 (보상 1)
- ...
추천시스템에서는 시스템이 "무엇을 보여줄지" 결정하는 한 번의 기회가 라운드다. 구체적으로는 구현에 따라 다른데, 넷플릭스처럼 홈 화면을 열 때 행 배치를 결정하면 페이지 로드 1회가 1라운드이고, 피드형 서비스에서 스크롤할 때마다 새 콘텐츠를 불러오면 그때마다가 1라운드다. 유저가 클릭하거나 무시한 결과는 해당 라운드의 보상으로 기록되어, 다음 라운드의 결정에 반영된다.
Regret (후회)
이 개념이 MAB에서 가장 중요하다. 만약 우리가 처음부터 어떤 머신이 제일 좋은지 알았다면, 매 라운드마다 그 머신만 당겼을 것이다. 하지만 현실에서는 모르기 때문에 이것저것 시도하면서 알아내야 한다. 그 과정에서 최선이 아닌 선택을 하게 되고, 최선의 선택을 했을 때와의 차이가 누적된다.
예를 들어보자. 5대의 슬롯머신이 있고, 각각의 진짜 평균 보상(우리는 모르는 값)이 이렇다고 하자:
머신 1번 2번 3번 ⭐ 4번 5번 평균 보상 0.3 0.4 0.7 0.2 0.5
3번 머신이 제일 좋지만 우리는 이걸 모른다. 그래서 이것저것 시도한다:
- 1라운드: 1번 머신 선택 → 1번의 평균 보상은 0.3, 최선(3번)은 0.7 → regret = 0.7 - 0.3 = 0.4
- 2라운드: 5번 머신 선택 → 5번의 평균 보상은 0.5, 최선(3번)은 0.7 → regret = 0.7 - 0.5 = 0.2
- 3라운드: 3번 머신 선택 → 최선을 골랐다! → regret = 0.7 - 0.7 = 0
이걸 전부 더하면 cumulative regret(누적 후회) = 0.4 + 0.2 + 0 = 0.6이 된다. 만약 처음부터 3번만 골랐다면 regret은 0이었을 것이다.
좋은 MAB 알고리즘이란, 이 cumulative regret을 최소화하는 알고리즘이다. 즉, 가능한 한 빨리 최선의 arm을 찾아내서, 불필요한 탐색으로 인한 손해를 줄이는 것이 목표다.
왜 이게 어려운가?
얼핏 보면 간단해 보인다. "몇 번 시도해보고 제일 좋은 거 고르면 되지 않나?" 하지만 함정이 있다:
- 몇 번 해보고 안 됐다고 포기하면 손해다 — 아까 표에서 1번 머신의 평균 보상은 0.3이었다. 그런데 만약 1번을 딱 2번 당겼는데 둘 다 동전이 안 나왔다면? "1번은 별로네" 하고 넘어갈 수 있다. 하지만 2번은 너무 적은 시도다. 운이 나빴을 뿐이지 더 당겨보면 평균에 수렴할 수 있다. 반대로, 진짜 제일 좋은 3번 머신도 처음 2번 당겼을 때 운 나쁘게 둘 다 안 나올 수 있다. 적게 시도한 arm을 너무 일찍 포기하면, 최선의 선택을 영영 놓칠 수 있다.
- 탐색에는 비용이 든다 — 새로운 arm을 시도할 때마다 그 라운드에서는 지금까지 알려진 최선의 arm을 포기하는 셈이다. 탐색을 너무 많이 하면 보상이 떨어진다.
- 시간이 제한되어 있다 — 무한히 시도할 수 있다면 모든 arm을 충분히 테스트하면 된다. 하지만 현실에서는 유저가 이탈하기 전에 빠르게 좋은 추천을 해야 한다.
이 딜레마가 바로 Exploration-Exploitation Tradeoff이다. 이제 이 개념들을 수학적으로 정의해보자.
Problem Formulation
$K$개의 arm(선택지)이 있고, 각 arm $i$는 미지의 보상 분포 $P_i$를 가진다. 매 라운드 $t$에서 하나의 arm $a_t$를 선택하면 보상 $r_t \sim P_{a_t}$를 받는다.
목표는 $T$ 라운드 동안의 cumulative regret을 최소화하는 것이다:
$$R _T = \sum_{t=1}^{T} (\mu^* - \mu_{a_t})$$
여기서 $\mu_i$는 arm $i$의 평균 보상이고, $\mu^*$는 그 중 가장 높은 값이다:
$$\ mu^* = \max_i \mu_i$$
즉 모든 arm 중에서 제일 좋은 arm의 평균 보상이다. 슬롯머신 예시에서는 3번 머신의 0.7이 $\mu^*$에 해당한다.
앞의 슬롯머신 예시로 대입하면: $\mu^*$ = 3번 머신의 평균 보상 0.7이고, 1라운드에서 1번 머신($\mu_{a_1}$=0.3)을 골랐으면 그 라운드의 regret은 0.7 - 0.3 = 0.4다. 이걸 $T$라운드까지 전부 더한 것이 $R_T$, 즉 cumulative regret이다.
정리하면, MAB가 풀고자 하는 문제는 이것이다:
각 arm의 보상 분포를 모르는 상태에서, $T$번의 선택 기회 동안 총 보상을 최대화하고 싶다.
그러려면 빨리 좋은 arm을 찾아야 하는데(탐색), 탐색하는 동안은 손해를 감수해야 한다.
반대로 손해를 줄이려면 지금까지 제일 좋았던 arm만 골라야 하는데(활용), 그러면 더 좋은 arm을 발견할 기회를 잃는다.
이 탐색과 활용의 딜레마를 수학적으로 최적화하는 것, 즉 cumulative regret $R_T$를 최소화하는 전략을 찾는 것이 MAB 문제의 본질이다.
Classic Algorithms
MAB 문제를 푸는 대표적인 알고리즘은 세 가지다. 먼저 두 가지를 간단히 보고, 실무에서 가장 많이 쓰이는 Thompson Sampling을 깊이 다루겠다.
Epsilon-Greedy
가장 단순한 방법이다. 매 라운드마다 동전을 던진다:
- 확률 $\epsilon$ (예: 10%)로 → 랜덤 arm을 선택한다 (탐색)
- 확률 $1-\epsilon$ (예: 90%)로 → 지금까지 평균 보상이 가장 높았던 arm을 선택한다 (활용)
여기서 $\epsilon$은 내가 직접 정하는 하이퍼파라미터다:
- $\epsilon = 0.1$로 정하면 → 10%는 랜덤 탐색, 90%는 최선 활용
- $\epsilon = 0.3$으로 정하면 → 30%는 랜덤 탐색, 70%는 최선 활용
직관적이고 구현이 쉽지만, 단점이 있다. "$\epsilon$을 얼마로 정해야 하지?"를 사람이 결정해야 한다. 너무 크면 탐색을 과하게 하고, 너무 작으면 좋은 arm을 못 찾는다. 또한 이미 최선의 arm을 충분히 알아냈는데도 계속 같은 비율로 랜덤 탐색을 한다.
이런 한계 때문에, 뒤에서 소개할 Thompson Sampling이 실무에서 더 많이 쓰인다. Thompson Sampling은 사람이 정할 하이퍼파라미터가 없고, 데이터가 쌓이면서 탐색→활용 비율이 알아서 조절된다.
더 깊이 공부하고 싶다면:
- Reinforcement Learning: An Introduction, Chapter 2 — Sutton & Barto (무료 PDF) — 강화학습의 바이블. Chapter 2가 통째로 Multi-Armed Bandits이고, Epsilon-Greedy부터 차근차근 설명한다.
- Introduction to Multi-Armed Bandits — Aleksandrs Slivkins (arXiv) — MAB 이론을 체계적으로 정리한 서베이. Epsilon-Greedy의 regret 분석까지 다룬다.
UCB (Upper Confidence Bound)
"잘 모르는 arm에게 기회를 더 주자"는 아이디어다. 각 arm마다 두 가지를 합산해서 비교한다:
점수 = 평균 보상 추정치 + 불확실성 보너스
적게 시도한 arm일수록 보너스가 크다. 그래서 자연스럽게 한 번도 안 해본 arm을 먼저 시도하게 되고, 충분히 시도한 arm은 보너스가 줄어들어 실력(평균 보상)으로만 경쟁하게 된다. 이론적 보장이 강력하지만, 실무에서는 다음에 소개할 Thompson Sampling이 더 많이 쓰인다.
Thompson Sampling
Thompson Sampling은 1933년에 처음 제안되었지만, 2010년대에 들어서야 이론적 분석이 완성되면서 실무에서 가장 널리 쓰이는 MAB 알고리즘이 되었다. Google, Microsoft, Netflix 등이 실제 서비스에 적용하고 있다.
Thompson Sampling을 이해하려면 베이지안 추론이라는 도구가 필요하다. 어렵지 않다. 동전 던지기로 설명하겠다.
베이지안 추론: 동전 던지기로 이해하기
친구가 동전 하나를 줬다. "이 동전은 앞면이 잘 나오는 동전이야"라고 한다. 진짜일까? 직접 던져보자.
던지기 전 (사전 분포, Prior)
아직 한 번도 안 던졌으니, 앞면이 나올 확률이 얼마인지 전혀 모른다. 0%일 수도 있고, 50%일 수도 있고, 100%일 수도 있다. 이 "아직 아무것도 모르는 상태의 믿음"을 사전 분포(Prior)라고 한다.
수학적으로는 Beta 분포라는 것으로 표현한다. Beta 분포는 딱 두 개의 숫자 $(\alpha, \beta)$로 정의된다:
- $\alpha$: 앞면이 나온 횟수 (+1)
- $\beta$: 뒷면이 나온 횟수 (+1)
아무것도 모를 때는 $\text{Beta}(1, 1)$로 시작한다. 이건 "앞면 확률이 0\~100% 어디든 똑같이 가능하다"는 뜻이다. 완전히 평평한 분포다.
1번 던짐: 앞면!
앞면이 나왔으니 $\alpha$에 1을 더한다 → $\text{Beta}(2, 1)$
이 분포는 "앞면 확률이 높은 쪽으로 약간 쏠렸지만, 아직 확신은 없다"는 뜻이다. 1번 던져서 1번 앞면이 나왔으니 당연하다.
3번 더 던짐: 앞, 앞, 뒤
앞면 2번 추가, 뒷면 1번 추가 → $\text{Beta}(4, 2)$
지금까지 4번 중 3번 앞면. 분포가 70\~80% 부근에 몰리기 시작한다. 하지만 아직 4번밖에 안 던졌으니 분포가 넓다(불확실하다).
20번 더 던짐: 앞면 14번, 뒷면 6번
→ $\text{Beta}(18, 8)$
총 24번 중 17번 앞면. 분포가 65\~75% 부근에 뾰족하게 모인다. 데이터가 쌓일수록 우리의 믿음이 점점 더 확신에 찬다.
이렇게 데이터를 관측할 때마다 믿음(분포)을 업데이트하는 것이 베이지안 추론의 핵심이다. 업데이트된 분포를 사후 분포(Posterior)라고 한다.
Beta 분포 핵심 정리
- Beta 분포는 항상 0\~1 사이 값만 나오는 분포다. 확률도 0\~1 사이이므로, "확률을 추정"할 때 딱 맞다
- Beta(α, β)는 "성공 확률이 얼마일까?"에 대한 믿음을 나타내는 분포다
- 성공(앞면)을 관측하면 α에 1을 더한다
- 실패(뒷면)를 관측하면 β에 1을 더한다
- α, β가 커질수록 분포가 뾰족해진다 = 확신이 커진다
- 평균은 α / (α + β) 이다. 예를 들어 Beta(6, 2)이면 6/(6+2) = 0.75, 즉 "이 머신이 동전을 줄 확률이 대략 75%쯤 될 것 같다"는 뜻이다
- 보상이 베르누이 분포(성공=1, 실패=0)를 따를 때, 그 성공 확률을 추정하는 도구가 Beta 분포다. 베르누이가 문제, Beta가 풀이 도구인 셈이다
Thompson Sampling 알고리즘
이제 이걸 MAB에 적용해보자. 슬롯머신 5대가 있다. 각 머신의 "동전이 나올 확률"을 모른다. 각 머신마다 Beta 분포를 하나씩 붙여서, 시도할 때마다 업데이트하면 된다.
초기 상태:
- 1번 머신: Beta(1, 1) — 아무것도 모름
- 2번 머신: Beta(1, 1) — 아무것도 모름
- 3번 머신: Beta(1, 1) — 아무것도 모름
- 4번 머신: Beta(1, 1) — 아무것도 모름
- 5번 머신: Beta(1, 1) — 아무것도 모름
매 라운드마다 하는 일:
① 샘플링: 각 머신의 Beta 분포에서 숫자를 하나씩 랜덤으로 뽑는다
"분포에서 뽑는다"는 게 뭔 말일까? Beta(3, 5)는 "이 머신의 성공 확률이 대략 이 범위에 있을 것 같다"는 믿음이다. 평균은 3/(3+5) = 0.375인데, 8번밖에 안 해봤으니 확신이 없다. 그래서 분포가 넓게 퍼져 있다.
이 넓은 범위 안에서 주사위 굴리듯이 하나를 랜덤으로 꺼내는 것이 샘플링이다. 같은 Beta(3, 5)에서 뽑아도 0.28이 나올 수도 있고, 0.41이 나올 수도 있고, 0.15가 나올 수도 있다. 매번 다른 값이 나온다.
주의: "샘플링"과 "머신을 당기는 것"은 다르다!
- 샘플링 = 컴퓨터가 각 분포에서 숫자를 뽑아보는 것. 계산일 뿐이다. 비용이 없다.
- 머신을 당기는 것 = 실제로 arm을 선택해서 보상을 받는 것. 이게 진짜 행동이다.
그러니까 한 라운드에서 5개 머신을 다 당기는 게 아니다. 컴퓨터가 5개 분포에서 숫자를 각각 뽑아보고(계산), 가장 높은 값이 나온 머신 1개만 실제로 당긴다.
이 예시에서 보상은 동전이 나오면 1, 안 나오면 0이다. Beta 분포의 샘플링 값은 "이 머신에서 동전이 나올 확률"에 대한 추측값이다.
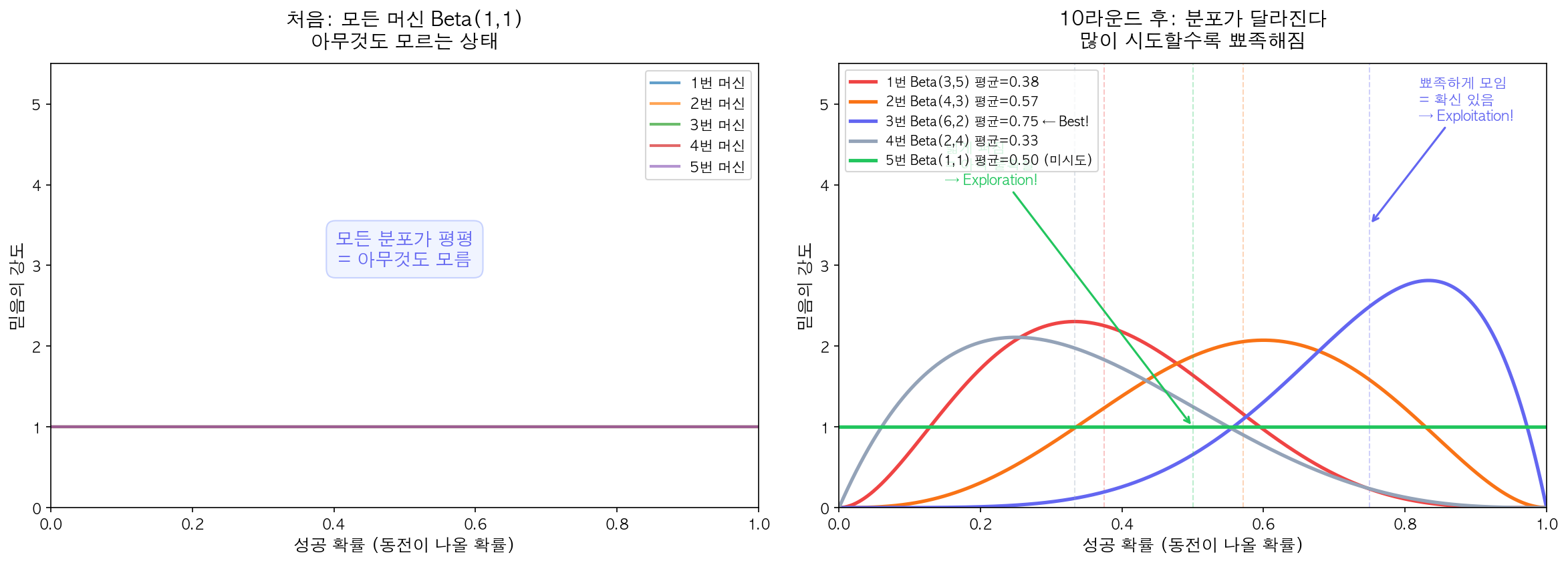
예를 들어 10라운드가 지나서 각 머신의 분포가 이렇게 됐다고 하자:
- 1번 머신: Beta(3, 5) → 평균은 3/8 = 0.375이지만, 랜덤으로 뽑으니 0.28이 나왔다
- 2번 머신: Beta(4, 3) → 뽑힌 값: 0.61
- 3번 머신: Beta(6, 2) → 뽑힌 값: 0.83
- 4번 머신: Beta(2, 4) → 뽑힌 값: 0.19
- 5번 머신: Beta(1, 1) → 뽑힌 값: 0.72
② 선택: 뽑힌 값이 가장 큰 arm을 선택한다 → 3번 머신(0.83)을 선택!
③ 업데이트: 3번 머신을 당겼더니 동전이 나왔다! → 3번의 $\alpha$에 1을 더한다 → Beta(7, 2)
이걸 반복하면 끝이다.
왜 이게 Exploration-Exploitation 균형을 알아서 잡는가?
아래 그래프를 보자. Thompson Sampling을 실제로 1000라운드 돌린 시뮬레이션이다. 라운드가 진행될수록 각 머신의 Beta 분포가 진짜 확률에 수렴하고, 분포가 뾰족해지는(확신이 커지는) 것을 볼 수 있다.
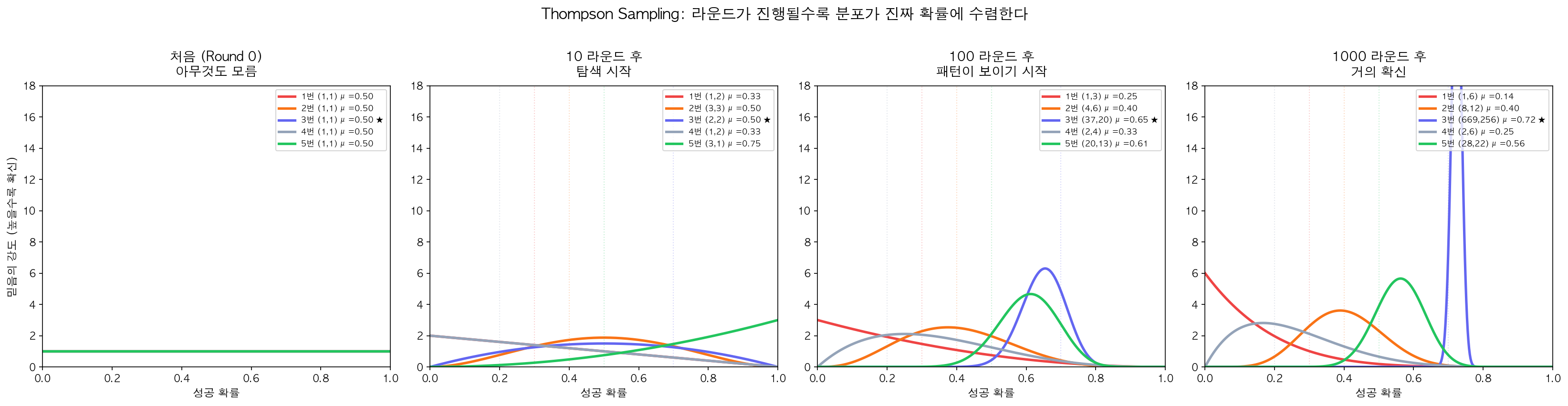
1000라운드 후 결과: 3번 머신(진짜 확률 0.7)이 923번 선택됐다. 나머지 머신들은 초반에 몇 번 시도된 뒤 자연스럽게 도태됐다. Thompson Sampling이 스스로 Exploration에서 Exploitation으로 전환한 것이다.
핵심은 불확실한 arm에서는 다양한 값이 뽑힌다는 것이다.
위 예시에서 5번 머신을 보자. Beta(1, 1)이니까 아직 한 번도 시도 안 했다. 이 분포에서 뽑으면 0.1이 나올 수도, 0.9가 나올 수도 있다. 범위가 넓다. 그래서 가끔은 높은 값이 뽑혀서 선택될 수 있다 → 이것이 Exploration(탐색)이다.
반면 3번 머신은 Beta(6, 2)다. 여러 번 시도해서 성공률이 높다는 걸 어느 정도 안다. 이 분포에서 뽑으면 대부분 0.6\~0.9 사이 값이 나온다. 그래서 높은 값이 자주 뽑혀서 자주 선택된다 → 이것이 Exploitation(활용)이다.
정리하면:
- 많이 시도한 좋은 arm → 분포가 높은 쪽에 뾰족 → 자주 선택됨 (Exploitation)
- 적게 시도한 arm → 분포가 넓음 → 가끔 높은 값이 뽑혀 선택됨 (Exploration)
- 많이 시도했는데 별로인 arm → 분포가 낮은 쪽에 뾰족 → 거의 선택 안 됨 (자연스러운 포기)
$\epsilon$이나 보너스 같은 하이퍼파라미터를 직접 정할 필요가 없다. 데이터가 쌓이면서 탐색과 활용의 비율이 알아서 조절된다. 이것이 Thompson Sampling이 실무에서 사랑받는 이유다.
Thompson Sampling 요약
- 각 arm마다 Beta(1, 1)로 시작
- 매 라운드: 각 arm의 Beta 분포에서 값을 샘플링
- 가장 높은 값이 나온 arm을 선택
- 보상을 관측하고 해당 arm의 분포를 업데이트 (성공 → α+1, 실패 → β+1)
이 4줄이 전부다. 하이퍼파라미터 튜닝 없이, 데이터가 쌓이면서 자동으로 Exploration→Exploitation으로 전환된다.
Thompson Sampling의 수학적 정의
위의 직관을 수학적으로 정리하면 다음과 같다. 논문을 읽을 때 이 표기법이 나온다:
- $a$ : action (arm 선택)
- $r$ : reward (보상, 예: 클릭 여부)
- $\theta$ : parameter (각 arm의 진짜 성공 확률, 우리가 모르는 값)
- $D = \{(a, r)\}$ : past observations (지금까지의 선택과 보상 기록)
- $P(D|\theta)$ : likelihood (데이터가 관측될 확률, 예: $D \sim Bernoulli(\theta)$)
- $P(\theta|D)$ : posterior (데이터를 본 후 업데이트된 믿음, 예: Beta 분포)
Thompson Sampling은 probability matching 전략이다. arm $a^*$를 선택할 확률이, 그 arm이 실제로 최적일 확률과 같아지도록 한다:
$\int I[a^* = \arg\max_a E(r|a, \theta)] \, P(\theta|D) \, d\theta$
이걸 직접 계산하는 건 어렵지만, posterior에서 샘플링하면 자연스럽게 이 확률에 맞게 선택된다. 그래서 "Beta 분포에서 뽑아서 가장 높은 arm을 고른다"는 간단한 알고리즘이 수학적으로도 올바른 것이다.
Conjugate prior: 보상이 Bernoulli일 때, Beta 분포를 prior로 쓰면 posterior도 Beta 분포가 된다. 이를 conjugate prior라고 하며, 업데이트가 $\alpha, \beta$에 1을 더하는 것만으로 끝나는 이유다:
$p_i \sim Beta(\alpha, \beta) \quad \rightarrow \quad \text{성공 관측} \rightarrow Beta(\alpha+1, \beta) \quad | \quad \text{실패 관측} \rightarrow Beta(\alpha, \beta+1)$
Thompson Sampling, MAB, Bayesian Optimization의 관계
Thompson Sampling은 MAB에서만 쓰이는 게 아니다. 더 넓은 Bayesian Optimization에서도 핵심 도구로 쓰인다.
- MAB: 선택지가 이산적(arm 1, 2, 3...)일 때 → Beta 분포 + Thompson Sampling
- Bayesian Optimization: 선택지가 연속적(가중치를 0.3으로? 0.7로?)일 때 → Gaussian Process + Thompson Sampling
예를 들어 LinkedIn은 피드 랭킹의 파라미터(가중치)를 수동 튜닝 대신, Gaussian Process로 파라미터 공간을 모델링하고 Thompson Sampling으로 다음에 시도할 파라미터를 고르는 Bayesian Optimization을 적용하고 있다. (LinkedIn Engineering, 2022 | Netflix ML Platform Meetup, 2019)
즉 Thompson Sampling은 MAB와 Bayesian Optimization 모두에서 쓰이는 범용 도구다.
Beta 분포만 쓰는 건 아니다
이 글에서는 보상이 0 또는 1(클릭/무시)인 경우로 설명했기 때문에 Beta 분포를 썼다. 하지만 보상의 형태에 따라 다른 분포를 쓴다:
| 보상 형태 | 예시 | 쓰는 분포 |
| 0 또는 1 | 추천 클릭 여부 | Beta 분포 |
| 연속 값 | 시청 시간, 구매 금액 | 정규분포 (Gaussian) |
| 연속 파라미터 공간 | 랭킹 가중치 최적화 | Gaussian Process |
핵심 원리는 동일하다: 분포에서 샘플링 → 가장 높은 arm 선택 → 결과로 분포 업데이트. 분포만 바뀔 뿐이다.
추천시스템 적용 시나리오
뉴스/콘텐츠 추천
새 기사가 계속 올라오는 환경에서, 클릭률을 모르는 새 기사(exploration)와 이미 클릭률이 높은 기사(exploitation) 사이의 균형이 필요하다. Yahoo!의 뉴스 추천 시스템이 대표적인 사례로, LinUCB를 적용하여 개인화된 뉴스 추천을 구현했다. (A Contextual-Bandit Approach to Personalized News Article Recommendation, Li et al., WWW 2010)
광고 배치
어떤 광고를 어떤 위치에 보여줄지 결정할 때, CTR(Click-Through Rate)을 최대화하기 위해 MAB를 사용한다.
A/B 테스트 대체
전통적 A/B 테스트는 실험 기간 동안 열등한 variant에도 동일한 트래픽을 배분한다. MAB 기반 테스트는 실시간으로 더 좋은 variant에 트래픽을 몰아주면서도 탐색을 병행한다.
Contextual Bandit
기본 MAB는 모든 유저에게 동일한 arm을 추천하지만, 실제로는 유저마다 선호가 다르다. Contextual Bandit은 유저/아이템의 특성 벡터 $x_t$를 고려한다.
$$r _t = x_t^\top \theta_{a_t} + \eta_t$$
대표 알고리즘인 LinUCB:
$$a _t = \arg\max_a \left[ x_t^\top \hat{\theta}_a + \alpha \sqrt{x_t^\top A_a^{-1} x_t} \right]$$
여기서 $A_a = D_a^\top D_a + I$는 디자인 행렬, $\hat{\theta}_a$는 릿지 회귀 추정치이다.
MAB vs 전통 추천시스템
| Collaborative Filtering | MAB | |
| 데이터 | 과거 로그 기반 (offline) | 실시간 상호작용 (online) |
| Cold Start | 취약 | 자연스럽게 해결 (exploration) |
| 적응 속도 | 재학습 필요 | 즉시 반영 |
| 개인화 | 유저-아이템 행렬 | Contextual Bandit |
| 피드백 루프 | 있음 (bias 누적) | 탐색으로 완화 |
실무에서는 둘을 결합하는 경우가 많다. CF로 후보군을 생성하고, MAB로 최종 노출 순서를 결정하는 2-stage 구조가 일반적이다.
정리
- MAB는 exploration-exploitation tradeoff를 체계적으로 다루는 프레임워크
- Epsilon-Greedy, UCB, Thompson Sampling이 대표 알고리즘
- 추천시스템에서 cold start, 실시간 적응, 공정한 노출에 효과적
- Contextual Bandit으로 확장하면 개인화까지 가능
- 실무에서는 CF/DL 기반 추천과 결합하여