추천시스템에서의 Multi-Armed Bandit-2

Introduction
Part 1에서는 MAB의 기본 개념과 Thompson Sampling까지 다뤘다. Part 2에서는 한 걸음 더 나아간다:
- Contextual Bandit — 유저마다 다른 추천이 필요할 때
- 실무에서 부딪히는 문제들 — delayed reward, batch update, non-stationary 환경
- 핵심 논문 가이드 — 어떤 순서로 읽으면 좋은지
- 직접 실험 — 벤치마크 데이터로 알고리즘 성능 비교
잠깐 — Thompson Sampling은 개인화가 안 되나?
Part 1에서 배운 Thompson Sampling은 강력하지만, 한 가지 큰 한계가 있다:
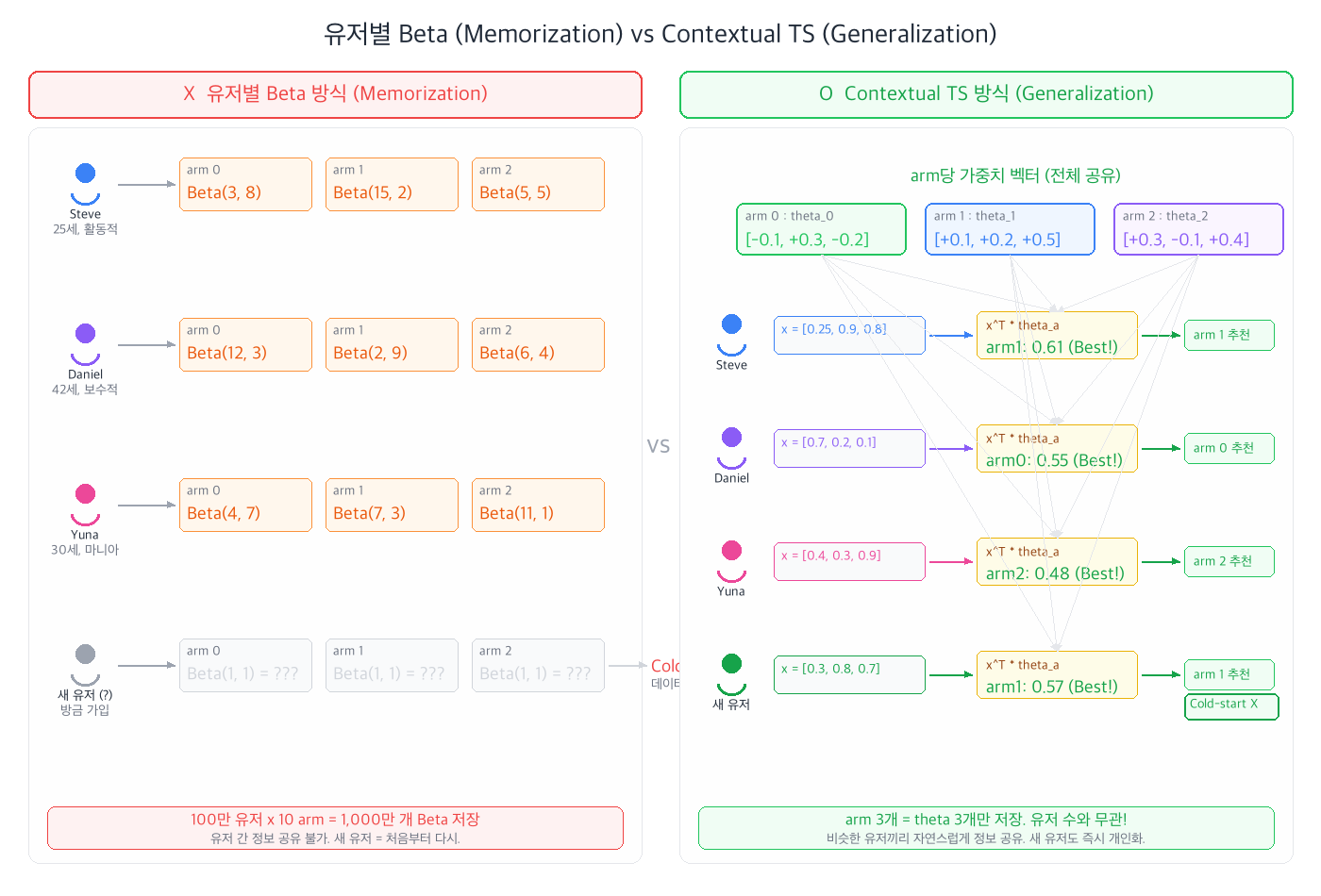
기본 Thompson Sampling은 개인화가 불가능하다.
각 arm마다 Beta(α, β) 하나만 유지하므로, "3번 arm이 제일 좋다"고 판단하면 모든 유저에게 3번을 추천한다. Steve든 Daniel이든 같은 추천을 받는다.
Q. 그러면 각 유저마다 따로 Beta(α, β)를 유지하면 개인화되는 거 아니야?
A. 이론적으로는 가능하지만, 실용적으로 불가능하다.
"유저별 Beta" 접근의 문제점:
- 저장 공간 폭발: 유저 100만 명 × arm 10개 = 1,000만 개의 Beta 분포를 저장해야 한다
- Cold-start: 새 유저가 오면 그 유저의 데이터가 없으니 Beta(1,1)부터 시작. 한참 동안 랜덤 추천을 받아야 한다
- 일반화 불가: 25세 남성 A가 쌓은 데이터를, 비슷한 25세 남성 B에게 전혀 활용할 수 없다. 각 유저가 완전히 독립
반면 Contextual TS는:
- 저장: arm당 가중치 벡터 θ 1개만 유지 (유저 수와 무관!)
- Cold-start 해결: "25세 남성은 신상품을 좋아한다"는 패턴을 학습하면, 새로운 25세 남성에게도 바로 적용
- 일반화: 비슷한 context를 가진 유저끼리 정보가 자연스럽게 공유된다
한 마디로, "유저별 Beta"는 memorization(암기)이고, "context × θ"는 generalization(일반화)이다. 이 차이가 실무에서 Contextual Bandit을 쓰는 핵심 이유다.
하지만 Thompson Sampling의 원리 자체("posterior에서 샘플링해서 가장 높은 arm 선택")는 개인화로 확장할 수 있다. 이것이 Contextual Thompson Sampling (= Linear TS)이다:
| 기본 TS (Part 1) | Contextual TS (Part 2) | |
| posterior | Beta(α, β) — 숫자 하나 | $N(\hat{\theta}, v^2 A^{-1})$ — 벡터 |
| 샘플링 | 숫자 1개를 뽑는다 | 벡터 1개를 뽑는다 |
| score 계산 | 뽑힌 숫자 그 자체 | $x_t^\top \times$ 뽑힌 벡터 (유저 context 반영) |
| 개인화 | 불가능 | 가능 |
| 예시 | 모든 유저에게 arm 3 추천 | Steve에게는 arm 1, Daniel에게는 arm 0 |
원리는 완전히 같다 — "posterior에서 샘플링해서 가장 높은 arm 선택". Beta 분포에서 뽑느냐, 정규분포에서 뽑느냐의 차이일 뿐이다. 이 확장이 어떻게 작동하는지, 그리고 왜 필요한지를 아래에서 자세히 다룬다.
Contextual Bandit
기본 MAB의 한계
Part 1의 Thompson Sampling은 강력하지만, 큰 가정이 하나 있다: 모든 유저에게 같은 arm이 최선이다. 슬롯머신 예시에서 3번 머신이 제일 좋으면, 누가 당기든 3번이 제일 좋다.
하지만 추천시스템에서는 이게 맞지 않다:
- Steve (25세, 트렌드에 민감, 매일 접속) — "신상품 추천"을 클릭할 확률이 높다
- Daniel (42세, 보수적 취향, 가끔 접속) — "인기 상품 추천"을 클릭할 확률이 높다
- Yuna (30세, 특정 카테고리 마니아) — "유사 상품 추천"을 클릭할 확률이 높다
유저의 특성(context)에 따라 최적의 arm이 달라진다. 이걸 다루는 것이 Contextual Bandit이다.
Context란?
매 라운드마다 arm을 고르기 전에, 시스템은 context 벡터 $x_t$를 관측한다. 이것은 현재 상황을 설명하는 정보다:
Context 예시유저 피처: 나이, 성별, 과거 클릭 이력, 가입 기간, 활동 빈도아이템 피처: 카테고리, 작성 시간, 길이, 인기도상황 피처: 시간대, 요일, 디바이스(모바일/데스크톱)
이런 정보들을 하나의 벡터로 합친 것이 context다. 예: $x_t = [25, 여, 모바일, 오후3시, 클릭이력...]$
기본 MAB vs Contextual Bandit
| 기본 MAB | Contextual Bandit | |
| 판단 기준 | arm의 전체 평균 보상 | context + arm의 조건부 보상 |
| 개인화 | 불가능 (모든 유저에게 같은 arm) | 가능 (유저마다 다른 arm) |
| 대표 알고리즘 | Thompson Sampling, UCB | LinUCB, Contextual Thompson Sampling |
LinUCB — 직관적 이해
LinUCB는 Contextual Bandit의 대표 알고리즘이다. 아이디어는 간단하다: context와 보상 사이의 관계를 선형 모델로 가정한다.
각 arm $a$에 대해:
기대 보상 = context 벡터 · arm의 가중치 벡터
수식으로 쓰면:
$$\ text{기대 보상} = x_t^\top \theta_a$$
여기서 $x_t$는 context 벡터, $\theta_a$는 arm $a$의 가중치 벡터다. 예를 들어 Steve의 context와 두 arm의 가중치가 이렇다고 하자:
| 나이(정규화) | 활동량 | 신상품 클릭 이력 | 기대 보상 | |
| Steve context $x_t$ | 0.25 | 0.9 | 0.8 | |
| arm 0 "인기 상품" $\theta_0$ | -0.1 | +0.3 | -0.2 | 0.085 |
| arm 1 "신상품" $\theta_1$ | +0.1 | +0.2 | +0.5 | 0.605 |
arm 0: (0.25×-0.1) + (0.9×0.3) + (0.8×-0.2) = 0.085
arm 1: (0.25×0.1) + (0.9×0.2) + (0.8×0.5) = 0.605
Steve에게는 arm 1(신상품 추천)의 기대 보상이 훨씬 높다 → arm 1을 선택! 같은 arm이라도 유저(context)에 따라 기대 보상이 달라진다. 이것이 Contextual Bandit의 핵심이다.
UCB와 마찬가지로, 기대 보상에 불확실성 보너스를 더한다. 잘 모르는 context-arm 조합에는 보너스가 커서 자연스럽게 Exploration이 일어난다.
이 알고리즘은 Yahoo!의 뉴스 추천 시스템에서 처음 대규모로 적용되어, 기존 방식 대비 CTR을 12.5% 향상시켰다. (A Contextual-Bandit Approach to Personalized News Article Recommendation, Li et al., WWW 2010)
실무에서 부딪히는 문제들
교과서의 MAB와 실제 서비스 사이에는 갭이 있다. 대표적인 문제들을 정리한다.
1. Delayed Reward
교과서: arm을 선택하면 보상이 즉시 관측된다.
현실: 클릭은 바로 알 수 있지만, 구매는 3일 뒤, 구독 취소는 한 달 뒤에나 알 수 있다.
보상이 늦게 들어오면, 그 사이에 이미 수천 번의 선택이 진행된다. 아직 보상을 모르는 선택들을 어떻게 처리할 것인가?
대표적인 해결책:
- 즉시 관측 가능한 proxy reward 사용 (구매 대신 장바구니 추가)
- 보상이 들어올 때까지 해당 샘플을 빼고 업데이트
- 보상 지연을 모델에 명시적으로 포함 (Chapelle, 2014)
2. Batch Update
교과서: 매 라운드마다 모델을 업데이트한다.
현실: 초당 수만 요청이 들어오는데, 매 요청마다 모델을 업데이트하면 시스템이 못 버틴다.
대표적인 해결책:
- 1시간/1일 단위로 모아서 batch update
- Mini-batch Thompson Sampling — 배치 안에서는 같은 분포로 샘플링하고, 배치가 끝나면 한번에 업데이트
- 실시간이 꼭 필요하면 approximate update (sufficient statistics만 유지)
3. Non-Stationary Environment
교과서: 각 arm의 보상 분포가 고정되어 있다.
현실: 유저 취향이 변하고, 트렌드가 바뀌고, 시즌이 달라진다. 지난달에 잘 먹혔던 전략이 이번 달에는 안 먹힐 수 있다.
대표적인 해결책:
- Sliding window — 최근 N일 데이터만 사용
- Discounted Thompson Sampling — 오래된 데이터에 가중치를 줄임
- Change detection — 보상 패턴이 급변하면 분포를 리셋
4. 편향된 로그 데이터로 시작할 때
새 MAB 시스템을 도입할 때, 기존 로그 데이터가 있다. 하지만 이 데이터는 기존 추천 시스템(또는 에디터 큐레이션)이 만든 것이므로, 특정 arm에 편향되어 있다.
예를 들어 기존 시스템이 "인기 상품 추천"만 했다면, 로그에는 이 전략의 보상 데이터만 풍부하고 나머지 전략은 데이터가 거의 없다.
대표적인 해결책:
- Off-policy evaluation (IPS, DR 추정량) — 편향된 로그에서 다른 정책의 성능을 추정
- Warm-start — 로그 데이터로 초기 분포를 설정하되, 불확실성을 크게 유지
- 초기에 의도적으로 uniform exploration을 강제한 뒤 전환
핵심 논문 가이드
아래 순서대로 읽으면 MAB의 이론 → 실무를 체계적으로 이해할 수 있다.
| 순서 | 논문 | 핵심 내용 | 왜 읽어야 하나 |
| 1 | Sutton & Barto, Ch.2 (2018) | MAB 기초, ε-greedy, UCB, gradient bandit | 모든 것의 출발점. 무료 PDF |
| 2 | Slivkins, Introduction to MAB (2019) | MAB 이론 종합 서베이, regret bounds | 수학적으로 깊이 이해하고 싶을 때 |
| 3 | Li et al., LinUCB (WWW 2010) | Contextual Bandit + 뉴스 추천 | Contextual Bandit의 시작점. Yahoo! 실제 적용 |
| 4 | Agrawal & Goyal, TS for Contextual Bandits (ICML 2013) | Thompson Sampling의 이론적 분석 | TS가 왜 잘 되는지 수학적 보장 |
| 5 | McInerney et al., Spotify BaRT (RecSys 2019) | 실제 서비스에서 bandit 적용 사례 | 이론→실무 갭을 이해하는 필독 논문 |
| 6 | Saito et al., Open Bandit Dataset (NeurIPS 2021) | Off-policy evaluation + 실제 A/B 데이터 공개 | 직접 실험할 수 있는 벤치마크 |
논문 1: Sutton & Barto, Reinforcement Learning Ch.2 (2018)
한 줄 요약: 강화학습의 바이블. Chapter 2가 MAB의 모든 기본 개념과 알고리즘을 한 곳에 정리한 교과서다.
Abstract / 도입부 해설
이 책은 별도의 abstract가 없지만, Chapter 2의 도입부에서 MAB 문제를 이렇게 정의한다:
"The most important feature distinguishing reinforcement learning from other types of learning is that it uses training information that evaluates the actions taken rather than instructs by giving correct actions."
— 강화학습이 다른 학습과 다른 핵심: 정답을 알려주는 게 아니라, 행동을 평가한다는 것
이게 무슨 뜻이냐면:
- 지도학습(Supervised Learning): "이 이미지의 정답은 고양이야" → 정답을 직접 알려준다
- 강화학습/MAB: 추천 A를 했더니 클릭이 안 됐다 → "이게 최선이었는지"는 모른다. 다른 걸 추천했으면 클릭했을 수도 있다
이 차이가 Exploration-Exploitation 딜레마의 근원이다. 정답을 모르니까, 직접 여러 가지를 시도해봐야(explore) 한다.
핵심 개념 1: Action-Value Method
가장 기본적인 아이디어: 각 arm의 가치(value)를 추정하고, 가치가 높은 arm을 선택한다.
$$Q _t(a) = \frac{\text{arm } a\text{를 선택해서 받은 보상의 합}}{\text{arm } a\text{를 선택한 횟수}}$$
이것이 sample-average method다. 단순히 평균을 내는 것. 대수의 법칙에 의해, 시도 횟수가 많아지면 진짜 기대 보상에 수렴한다.
주의: "가치(value)"라는 표현이 거창하지만, 결국 평균 보상이다. 슬롯머신을 100번 당겨서 평균 0.7만큼 보상을 받았으면, 이 머신의 가치 추정값은 0.7이다.
핵심 개념 2: Incremental Update (점진적 업데이트)
평균을 구하려면 모든 보상을 저장해야 할까? 아니다. 아래 공식 하나면 된다:
$$Q _{n+1} = Q_n + \frac{1}{n}[R_n - Q_n]$$
- $Q_n$: 현재까지의 추정값 (이전 평균)
- $R_n$: 이번에 받은 보상
- $R_n - Q_n$: prediction error — 예상과 실제의 차이
- $\frac{1}{n}$: step size — 새 데이터를 얼마나 반영할지
이 공식의 구조는 강화학습 전체에서 반복된다:
새 추정값 = 이전 추정값 + step size × (실제 - 예상)
이 패턴을 기억해두면 Q-learning, TD learning 등 모든 RL 알고리즘을 이해할 때 도움이 된다.
핵심 개념 3: ε-Greedy vs UCB vs Gradient Bandit
| 알고리즘 | arm 선택 방식 | Exploration 방식 | 장단점 |
| ε-Greedy | 확률 1-ε로 최고 arm, ε로 랜덤 | 무작위 (맹목적) | 간단하지만, 좋은 arm도 나쁜 arm도 같은 확률로 탐색 |
| UCB | $Q(a) + c\sqrt{\frac{\ln t}{N(a)}}$ | 불확실성 기반 (체계적) | 덜 시도한 arm에 보너스. 결정론적이라 구현 간단 |
| Gradient Bandit | $\pi(a) = \frac{e^{H(a)}}{\sum e^{H(b)}}$ (softmax) | preference 학습 | 보상의 절대값이 아닌 상대적 차이를 학습. baseline 필요 |
핵심 개념 4: Optimistic Initial Values (낙관적 초기값)
아주 간단하지만 효과적인 트릭이다:
- 모든 arm의 초기 추정값을 비현실적으로 높게 설정한다 (예: 진짜 보상이 0\~1 범위인데, 초기값을 5로 설정)
- 어떤 arm을 당겨도 보상이 초기값보다 낮으니, 추정값이 내려간다
- 아직 안 당긴 arm은 초기값(5)이 그대로이므로 가장 높다 → 자연스럽게 그쪽을 탐색
- 결과적으로 모든 arm을 초기에 골고루 탐색한 뒤, 점차 좋은 arm에 수렴한다
Figure 2.3의 핵심 메시지: Optimistic initial values (Q₁=5)를 쓴 greedy 방법이, realistic initial values (Q₁=0)를 쓴 ε-greedy보다 초기에 더 빠르게 최적 arm을 찾는다. 단, 이 트릭은 stationary 환경에서만 효과적이다 — non-stationary에서는 초기 탐색 이후 적응하지 못한다.
Figure 2.2: 10-Armed Testbed
이 챕터에서 가장 중요한 실험이다. 설정:
- 10개 arm, 각 arm의 진짜 가치 $q_*(a)$는 표준정규분포에서 뽑는다
- arm을 당기면 $q_*(a)$를 중심으로 분산 1인 정규분포에서 보상이 나온다
- 2000 라운드 × 2000번 반복하여 평균
결과:
- ε=0이면 (순수 greedy): 처음에 빠르지만 \~1.0 수준에서 정체. 잘못된 arm에 갇힌다
- ε=0.01이면: 느리지만 장기적으로 \~1.4까지 올라간다
- ε=0.1이면: 가장 빠르게 \~1.4에 도달. 하지만 10%는 항상 랜덤이라 최적 arm 선택률이 \~91%에서 정체
이 실험이 주는 교훈: Exploration 없이는 최적해를 찾을 수 없고, 너무 많은 exploration은 성능을 깎는다.
읽기 가이드
- Section 2.1\~2.4 (action-value, ε-greedy, incremental): 필수. 모든 것의 기초
- Section 2.6 (optimistic initial values): 읽으면 좋다. 구현이 간단하고 효과적
- Section 2.7 (UCB): 필수. 이론적으로 중요한 알고리즘
- Section 2.8 (gradient bandit): policy gradient의 시작. 딥러닝 기반 bandit으로 넘어갈 때 필요
- Section 2.9 (associative search): Contextual Bandit의 시작. Part 2의 핵심 주제
- 무료 PDF: 공식 페이지
논문 2: Introduction to Multi-Armed Bandits (Slivkins, 2019)
한 줄 요약: MAB 이론의 모든 것을 396페이지에 담은 서베이. "왜 이 알고리즘이 좋은가"를 수학적으로 증명한다.
Abstract 해석
"Multi-armed bandit (MAB) is a framework for algorithms that make decisions over time under uncertainty. An algorithm repeatedly chooses from a fixed set of alternatives ("arms"), and receives a "reward" for each choice. The algorithm's goal is to maximize the total reward over time."
→ MAB는 불확실성 하에서 시간에 걸쳐 결정을 내리는 알고리즘 프레임워크다. 고정된 선택지(arm) 중 하나를 반복 선택하고, 보상을 받는다. 목표는 총 보상을 최대화하는 것.
"The fundamental tension is between exploitation (choosing an arm with high estimated reward) and exploration (trying out different arms to learn more)."
→ 핵심 긴장: exploitation (보상 높다고 추정되는 arm 선택) vs exploration (더 배우기 위해 다른 arm 시도). 이 trade-off를 수학적으로 정량화하는 것이 이 서베이의 목표다.
핵심 개념 1: Regret — 알고리즘의 성능을 측정하는 방법
MAB에서 알고리즘이 "얼마나 좋은지"를 어떻게 측정할까? Regret(후회)이라는 개념을 쓴다:
$$\ text{Regret}(T) = T \cdot \mu^* - \sum_{t=1}^{T} \mu_{a_t}$$
- $T$: 총 라운드 수
- $\mu^*$: 최적 arm의 기대 보상 (진짜 최고)
- $\mu_{a_t}$: 라운드 $t$에서 선택한 arm의 기대 보상
- 직관: "매번 최적 arm을 골랐으면 받았을 보상" - "실제로 받은 보상"
Regret이 작을수록 좋은 알고리즘이다. 이상적으로는 0에 가까워야 한다. 하지만 0이 될 수 있을까?
핵심 개념 2: Regret Lower Bound — 이론적 한계
Theorem (Lai & Robbins, 1985; Auer et al., 2002)
K개의 arm이 있고 T 라운드를 진행할 때, 어떤 알고리즘을 쓰더라도 최악의 경우 regret이 다음보다 작아질 수 없다:
$\text{Regret}(T) = \Omega(\sqrt{KT})$
이것은 정보 이론적 한계다. 각 arm이 얼마나 좋은지 알기 위해서는 최소한 이만큼의 "탐색 비용"을 지불해야 한다.
이게 왜 중요하냐면:
- 어떤 사람이 "내 알고리즘의 regret은 $O(\sqrt{KT})$다"라고 말하면 → 이론적으로 최적에 가까운 알고리즘이라는 뜻
- "내 알고리즘의 regret은 $O(T)$다"라고 말하면 → 별로 안 좋다. 랜덤 선택과 같은 급(order)이다
- 예: ε-Greedy의 regret은 $O(\varepsilon T)$ → 선형이다. ε가 0이 아닌 한, 시간이 흐를수록 regret이 계속 커진다
핵심 개념 3: 각 알고리즘의 Regret Bound
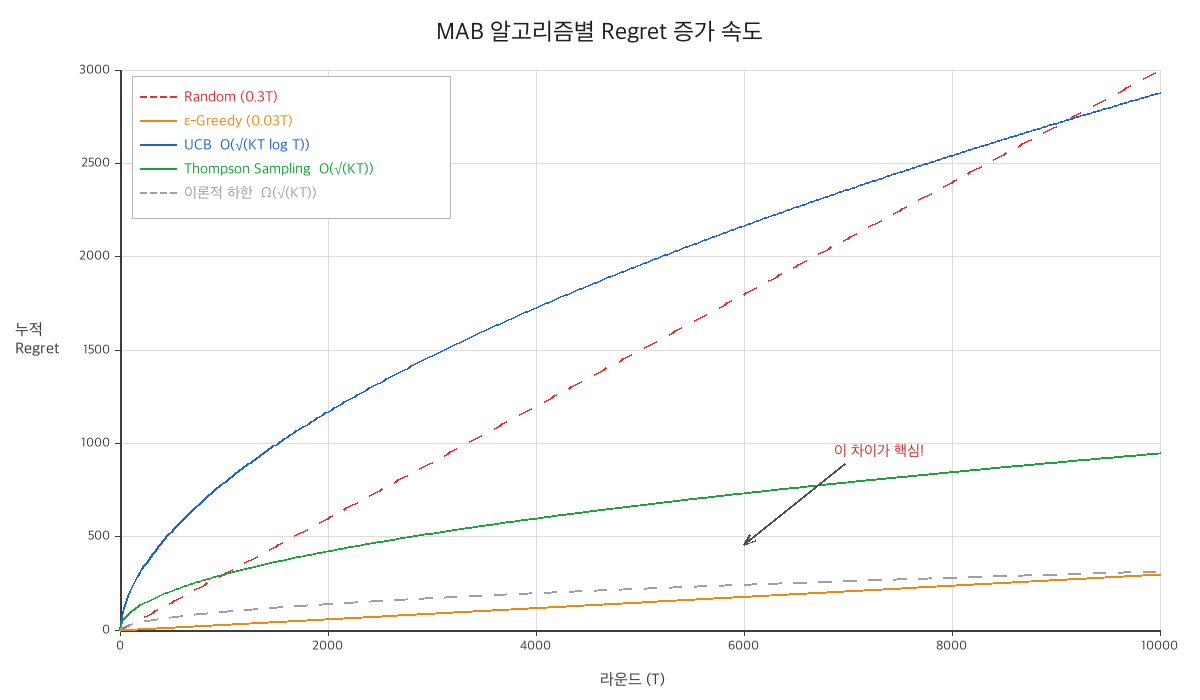
| 알고리즘 | Regret Bound | Order | 최적? |
| Random | $(\mu^* - \bar{\mu}) \cdot T$ | $O(T)$ | 최악 |
| ε-Greedy (고정 ε) | $O(\varepsilon T + \frac{K}{\varepsilon})$ | $O(T)$ (선형) | 아니오 |
| UCB | $O(\sqrt{KT \log T})$ | $\tilde{O}(\sqrt{KT})$ | 거의 최적 (log 차이) |
| Thompson Sampling | $O(\sqrt{KT \log K})$ | $\tilde{O}(\sqrt{KT})$ | 거의 최적 |
| 이론적 하한 | — | $\Omega(\sqrt{KT})$ | 넘을 수 없는 벽 |
핵심 개념 4: Adversarial Bandit
지금까지의 모든 분석은 stochastic setting — 각 arm의 보상이 고정된 확률 분포에서 나온다고 가정했다. 하지만 현실에서는?
- 경쟁자가 가격을 바꾸면 내 arm의 보상이 변한다
- 트렌드가 바뀌면 어제 좋았던 추천이 오늘은 안 먹힌다
- 심지어 "적대적"으로(adversarially) 보상이 결정될 수도 있다
이런 경우를 다루는 것이 Adversarial Bandit이고, 대표 알고리즘이 EXP3 (Exponential-weight algorithm for Exploration and Exploitation)다. EXP3의 regret bound도 $O(\sqrt{KT \log K})$로, stochastic보다 약간 나쁘지만 여전히 sublinear다.
읽기 가이드
396페이지 전부 읽을 필요 없다. 추천 경로:
- Chapter 1 (Introduction): 필수. 문제 정의와 regret 개념
- Chapter 2 (Lower bounds): 핵심 정리(Theorem)의 statement만 이해하면 된다. 증명은 스킵 가능
- Chapter 3 (UCB): 필수. UCB 알고리즘과 regret 분석
- Chapter 4 (Thompson Sampling): 필수. Bayesian approach
- Chapter 6 (Adversarial Bandits): EXP3를 이해하고 싶다면
- Chapter 8 (Contextual Bandits): 추천시스템 적용에 핵심
- arXiv 링크
논문 3: A Contextual-Bandit Approach to Personalized News Article Recommendation (Li et al., WWW 2010)
한 줄 요약: LinUCB 알고리즘을 제안하고, Yahoo! 뉴스 추천에 적용하여 CTR 12.5% 향상. Contextual Bandit의 시작.
Abstract 완전 해석
"Personalized web services strive to adapt their services (e.g., news, advertisements, etc.) to individual users by making use of both content and user information."
→ 개인화 웹 서비스는 콘텐츠와 유저 정보를 모두 활용하여 서비스를 개인에게 맞추려 한다.
"In this work, we model personalized recommendation of news articles as a contextual bandit problem, a principled approach in which a learning algorithm sequentially selects articles to serve users based on contextual information about the users and articles, while simultaneously adapting its article-selection strategy based on user-click feedback to maximize total user clicks."
→ 뉴스 기사의 개인화 추천을 contextual bandit 문제로 모델링했다. 유저와 기사의 contextual 정보를 기반으로 기사를 순차적으로 선택하고, 유저 클릭 피드백으로 전략을 계속 적응시켜 총 클릭을 최대화한다.
"We propose a new algorithm, LinUCB, which has a provably efficient performance guarantee. Through a large-scale evaluation on a real-world dataset from Yahoo! Front Page, we demonstrate that our approach achieves a 12.5% CTR lift compared to context-free bandit algorithms."
→ LinUCB라는 새 알고리즘을 제안했고, 이론적 성능 보장이 있다. Yahoo! Front Page의 실제 데이터로 평가하여 context-free bandit 대비 CTR 12.5% 향상을 달성했다.
문제 설정: Yahoo! Today Module
2010년 당시 Yahoo!의 메인 페이지에는 "Today Module"이라는 뉴스 추천 슬롯이 있었다:
- 화면 중앙에 뉴스 기사 1개를 크게 보여주는 슬롯
- 매 방문마다 수십\~수백 개의 후보 기사 중 하나를 선택해야 한다
- 유저가 클릭하면 reward=1, 무시하면 reward=0 (Bernoulli reward)
- 매일 수백만 번의 추천이 일어난다
핵심 질문: "어떤 기사를 보여줘야 이 유저가 클릭할 확률이 높을까?"
Context Feature 구성
논문에서 사용한 context 벡터 $x_t \in \mathbb{R}^d$:
| 피처 종류 | 구체적 내용 | 차원 |
| 유저 피처 | 나이 (인구통계), 성별, 행동 카테고리 (1000개 뉴스 카테고리에 대한 클릭 이력을 PCA) | 6차원 |
| 기사 피처 | URL 카테고리, 에디터가 붙인 토픽, TF-IDF 벡터를 PCA | 6차원 |
| 결합 벡터 | 유저 피처 ⊗ 기사 피처 (outer product) + bias | 총 \~36차원 |
유저 피처 6차원 × 기사 피처 6차원 = 36차원의 interaction 피처. 이렇게 하면 "25세 남성이 스포츠 기사를 좋아한다"는 패턴을 잡을 수 있다.
LinUCB 알고리즘 상세
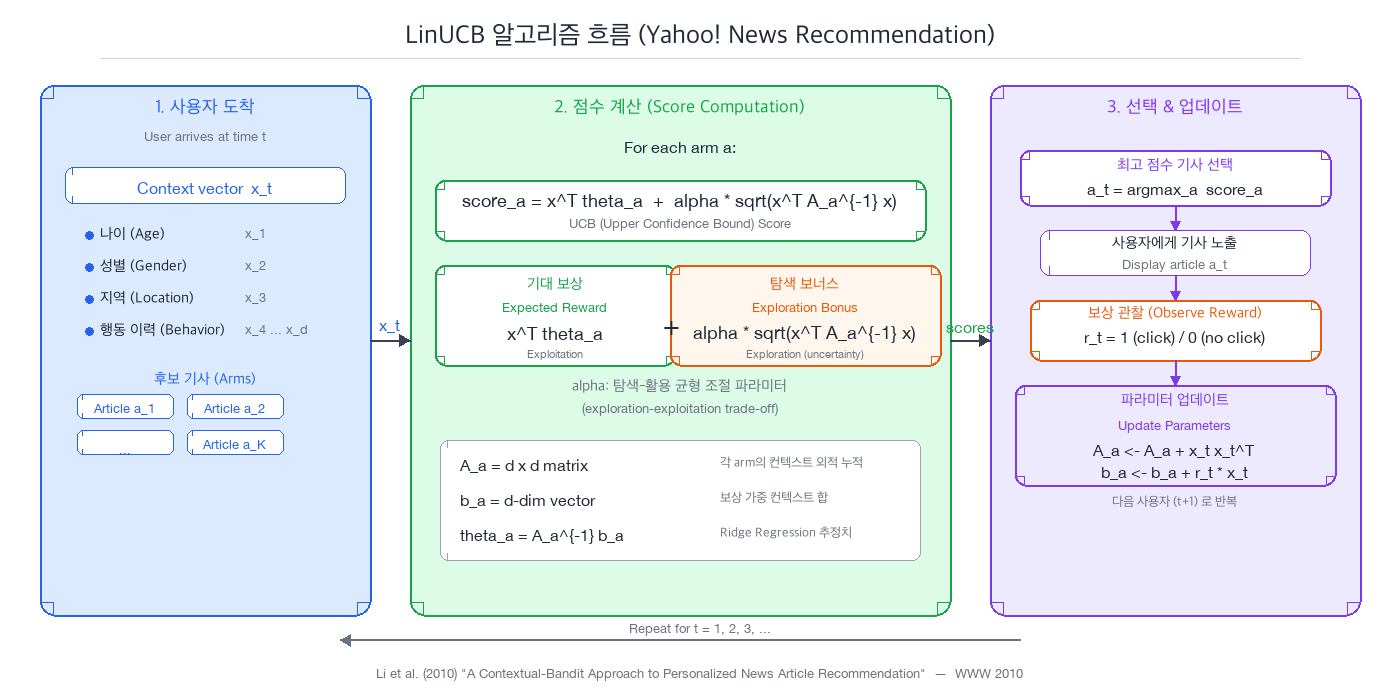
각 arm(기사) $a$에 대해 보상을 선형 모델로 가정한다:
$$r _{t,a} = x_{t,a}^\top \theta_a^* + \epsilon_t$$
- $x_{t,a}$: 시점 $t$에서 유저-기사 쌍의 context 벡터
- $\theta_a^*$: arm $a$의 진짜 가중치 벡터 (우리가 모르는 값, 학습해야 함)
- $\epsilon_t$: 노이즈
$\theta_a^*$를 추정하기 위해 Ridge Regression을 사용한다:
$$\ hat{\theta}_a = A_a^{-1} b_a$$
여기서:
- $A_a = D_a^\top D_a + I_d$ — arm $a$의 context 벡터들의 Gram matrix + 정규화
- $b_a = D_a^\top c_a$ — context 벡터와 보상의 내적
- $D_a$: arm $a$가 선택될 때마다 쌓이는 context 벡터 행렬
- $c_a$: 대응하는 보상 벡터
직관: $A_a$는 "arm $a$에 대해 얼마나 많은 정보를 모았는가"를 나타낸다. context를 많이 본 방향에서는 $A_a$가 크고, 적게 본 방향에서는 작다. $A_a^{-1}$은 그 역수이므로, 정보가 적은 방향에서 불확실성이 크다.
arm 선택 공식:
$$a _t = \arg\max_a \left( x_{t,a}^\top \hat{\theta}a + \alpha \sqrt{x \right)$$}^\top A_a^{-1} x_{t,a}
- 첫 번째 항 $x_{t,a}^\top \hat{\theta}_a$: exploitation — 현재 추정으로 기대 보상이 높은 arm
- 두 번째 항 $\alpha \sqrt{x_{t,a}^\top A_a^{-1} x_{t,a}}$: exploration bonus — 불확실성이 큰 arm
- $\alpha \geq 0$: exploration 강도를 조절하는 하이퍼파라미터
Algorithm 1: LinUCB (Pseudocode)
LinUCB with Disjoint Linear Models
입력: α > 0 (exploration parameter)
for t = 1, 2, 3, ... do
context x_t를 관측
for 각 arm a ∈ A_t do
if arm a가 처음이면:
A_a ← I_d (d×d 단위행렬)
b_a ← 0 (d차원 영벡터)
θ̂_a ← A_a⁻¹ b_a
score_a ← x_t^T θ̂_a + α √(x_t^T A_a⁻¹ x_t)
end for
a_t ← argmax_a score_a // 가장 높은 점수의 arm 선택
reward r_t를 관측 (클릭=1, 무시=0)
A_{a_t} ← A_{a_t} + x_t x_t^T // 정보 행렬 업데이트
b_{a_t} ← b_{a_t} + r_t x_t // 보상 벡터 업데이트
end for
핵심 포인트: 업데이트가 $A_a$에 $x_t x_t^\top$를 더하고, $b_a$에 $r_t x_t$를 더하는 것 두 줄이 전부다. Ridge regression의 sufficient statistics만 유지하면 되기 때문에, 과거 데이터를 저장할 필요가 없다. 이것이 LinUCB가 대규모 시스템에서 실용적인 이유다.
Offline Evaluation: Replay Method
이 논문의 또 다른 중요한 기여는 replay method라는 offline evaluation 기법이다.
문제: 새 알고리즘을 평가하려면 실제 서비스에 배포해야 할까? 위험하다.
Replay method의 아이디어:
- 기존 시스템의 로그가 있다: (context, action, reward) 삼중쌍
- 로그를 순서대로 읽으면서, 새 알고리즘이 같은 action을 선택했을 때만 해당 데이터를 사용
- 다른 action을 선택했으면 그 데이터는 건너뛴다
이 방법이 unbiased estimator가 되려면, 기존 시스템의 action이 uniform random이거나 known propensity여야 한다.
실험 결과 상세
- 데이터: Yahoo! Front Page 로그 약 4,500만 이벤트 (2009년 5월 1일\~10일)
- 후보 기사: 매 시점 약 20개
- 평가 지표: CTR (Click-Through Rate)
알고리즘 상대 CTR 향상 비고 Random baseline 모든 기사를 동일 확률로 노출 ε-Greedy (context-free) +5\~8% 유저 정보 안 쓰고, 전체 CTR만으로 학습 UCB (context-free) +6\~9% 유저 정보 안 쓰고, 불확실성만 활용 LinUCB (disjoint) +12.5% 유저 + 기사 context 활용 LinUCB (hybrid) +12.8% 공유 파라미터 + 개별 파라미터
왜 12.5%가 대단한가? 뉴스 추천에서 CTR은 보통 1\~3% 수준이다. 12.5% 향상은 상대적으로 보면 기존 CTR 2%가 2.25%가 되는 것이다. 이게 매일 수백만 노출에 적용되면 클릭 수가 수십만 개 차이난다.
Hybrid Model (확장)
Disjoint model은 각 arm이 독립적인 $\theta_a$를 가진다. 하지만 기사 간에 공통된 패턴이 있을 수 있다 (예: "25세 남성은 스포츠 기사를 좋아한다"는 패턴은 모든 스포츠 기사에 공통).
Hybrid model:
$$r _{t,a} = z_{t,a}^\top \beta^* + x_{t,a}^\top \theta_a^* + \epsilon_t$$
- $\beta^*$: 모든 arm이 공유하는 파라미터 — "스포츠 기사 + 젊은 남성 = 높은 클릭"
- $\theta_a^*$: 각 arm 고유의 파라미터 — "이 특정 기사는 제목이 자극적이라 추가로 클릭률이 높다"
- 새 기사가 등장해도 $\beta^*$에서 정보를 공유하므로 cold-start 문제를 완화한다
- arXiv 링크
논문 4: Thompson Sampling for Contextual Bandits with Linear Payoffs (Agrawal & Goyal, ICML 2013)
한 줄 요약: Thompson Sampling이 Contextual Bandit에서도 이론적으로 최적에 가까운 regret bound를 달성함을 세계 최초로 증명
Abstract 완전 해석
"Thompson Sampling is one of the oldest heuristics for multi-armed bandit problems. It is a Bayesian algorithm that has shown excellent empirical performance, but theoretical understanding of it has been limited until recently."
→ Thompson Sampling은 MAB에서 가장 오래된 휴리스틱(1933년) 중 하나다. 경험적으로는 뛰어난 성능을 보여왔지만, 이론적 이해가 부족했다.
"In this paper, we design and analyze a generalization of Thompson Sampling for the stochastic contextual multi-armed bandit problem with linear payoff functions. We prove a regret bound of Õ(d√T) for this algorithm, which matches (up to polylog factors) the best known bound for any algorithm for this problem."
→ 이 논문에서 Thompson Sampling을 선형 보상 함수를 가진 contextual MAB로 확장했다. Regret bound $\tilde{O}(d\sqrt{T})$를 증명했고, 이는 이 문제에 대해 알려진 최적 bound와 (polylog 차이로) 일치한다.
왜 이 논문이 중요한가?
Thompson Sampling의 역사를 짧게 보면:
- 1933년: William R. Thompson이 제안. 최초의 MAB 알고리즘 중 하나
- 1933\~2010년 (약 80년간!): 경험적으로 잘 되지만, 왜 잘 되는지 아무도 증명하지 못함
- 2012년: Agrawal & Goyal이 기본 MAB에서 TS의 regret bound를 최초 증명
- 2013년 (이 논문): Contextual MAB로 확장
80년 동안 "경험적으로 좋은데 왜 좋은지 모르겠다"는 상태였다는 것이 놀랍다. 이 논문이 그 빈칸을 채웠다.
알고리즘: Linear Thompson Sampling
Part 1에서 배운 Thompson Sampling을 떠올려보자:
- 기본 TS: 각 arm의 성공 확률 $\theta_a$에 대해 Beta 분포를 유지. Beta에서 샘플링하여 가장 높은 arm 선택
- Linear TS: 각 arm의 가중치 벡터 $\theta_a \in \mathbb{R}^d$에 대해 정규분포(Gaussian)를 유지
Linear Thompson Sampling
for t = 1, 2, 3, ... do
context x_t를 관측
for 각 arm a do
// posterior에서 샘플링
θ̃_a \~ N(θ̂_a, v² A_a⁻¹)
score_a ← x_t^T θ̃_a
end for
a_t ← argmax_a score_a
reward r_t를 관측
A_{a_t} ← A_{a_t} + x_t x_t^T
b_{a_t} ← b_{a_t} + r_t x_t
θ̂_{a_t} ← A_{a_t}⁻¹ b_{a_t}
end for
LinUCB와 비교:
| LinUCB | Linear Thompson Sampling | |
| score 계산 | $x^\top \hat{\theta} + \alpha \sqrt{x^\top A^{-1} x}$ | $x^\top \tilde{\theta}$ ($\tilde{\theta} \sim N(\hat{\theta}, v^2 A^{-1})$) |
| Exploration 방식 | 결정론적 보너스 (항상 같은 값) | 확률적 샘플링 (매번 다른 값) |
| 하이퍼파라미터 | $\alpha$ (exploration 강도) | $v$ (posterior 분산 스케일) |
| Regret bound | $O(d\sqrt{T \log T})$ | $\tilde{O}(d\sqrt{T})$ |
| 실험 성능 | 좋음 | 일관되게 더 좋음 |
핵심 직관: LinUCB는 불확실성 보너스를 "항상 같은 크기"로 더한다. TS는 posterior에서 "랜덤하게" 샘플링하므로, 때로는 크게 때로는 작게 탐색한다. 이 확률적 탐색이 더 효율적이라는 것이 실험 결과의 일관된 메시지다.
Regret Bound 해석
$$\ text{Regret}(T) = \tilde{O}(d\sqrt{T})$$
이것이 의미하는 바:
- $d$: context 벡터의 차원. 피처가 많을수록 학습할 것이 많으므로 regret이 커진다
- $\sqrt{T}$: sublinear! 라운드가 10배 늘어나면 regret은 \~3.16배만 증가한다
- $\tilde{O}$: polylog 팩터($\log$ 등)를 숨긴 표기. "대략 이 order"라는 뜻
- 이것은 minimax optimal에 (polylog 차이로) 일치한다 — 즉, 이보다 근본적으로 좋은 알고리즘은 존재할 수 없다
읽기 가이드
- Section 1-2: 문제 정의와 알고리즘. 이것만 읽어도 TS를 구현할 수 있다
- Theorem 1: main result. statement만 이해하면 된다
- Section 3-4 (증명): 매우 기술적. 전문 연구자가 아니면 스킵 가능
- Section 5 (실험): TS vs UCB 비교 그래프. 직관적으로 이해할 수 있다
- arXiv 링크
논문 5: Explore, Exploit, and Explain: Personalizing Explainable Recommendations with Bandits (McInerney et al., Spotify, RecSys 2019)
한 줄 요약: Spotify가 실제 홈 화면 추천에 bandit을 적용한 산업 논문. Explore + Exploit + Explain 3가지를 동시에 달성.
Abstract 완전 해석
"The multi-armed bandit is an important framework for balancing exploration with exploitation in recommendation. Existing approaches focus on the tradeoff between exploration and exploitation, while ignoring the third important factor of explanation."
→ MAB는 추천에서 Exploration-Exploitation 균형을 잡는 중요한 프레임워크다. 기존 접근법은 Explore-Exploit 균형에만 집중하고, 세 번째 중요한 요소인 설명(Explanation)을 무시한다.
"We introduce a system called Bandit-based Recommendations as Treatments (BaRT), which uses a contextual bandit to jointly optimize exploration, exploitation, and explanation. The system models each recommendation as a treatment, with the explanation as part of that treatment."
→ BaRT (Bandit-based Recommendations as Treatments) 시스템을 소개한다. Contextual bandit으로 Exploration, Exploitation, Explanation을 동시에 최적화한다. 각 추천을 "treatment"로, 설명을 그 treatment의 일부로 모델링한다.
"We present results from a large-scale online experiment on the Spotify music streaming platform, demonstrating significant improvements in user satisfaction."
→ Spotify 음악 스트리밍 플랫폼에서 대규모 온라인 실험 결과를 제시하며, 유저 만족도의 유의미한 향상을 보인다.
문제 설정: Spotify 홈 화면
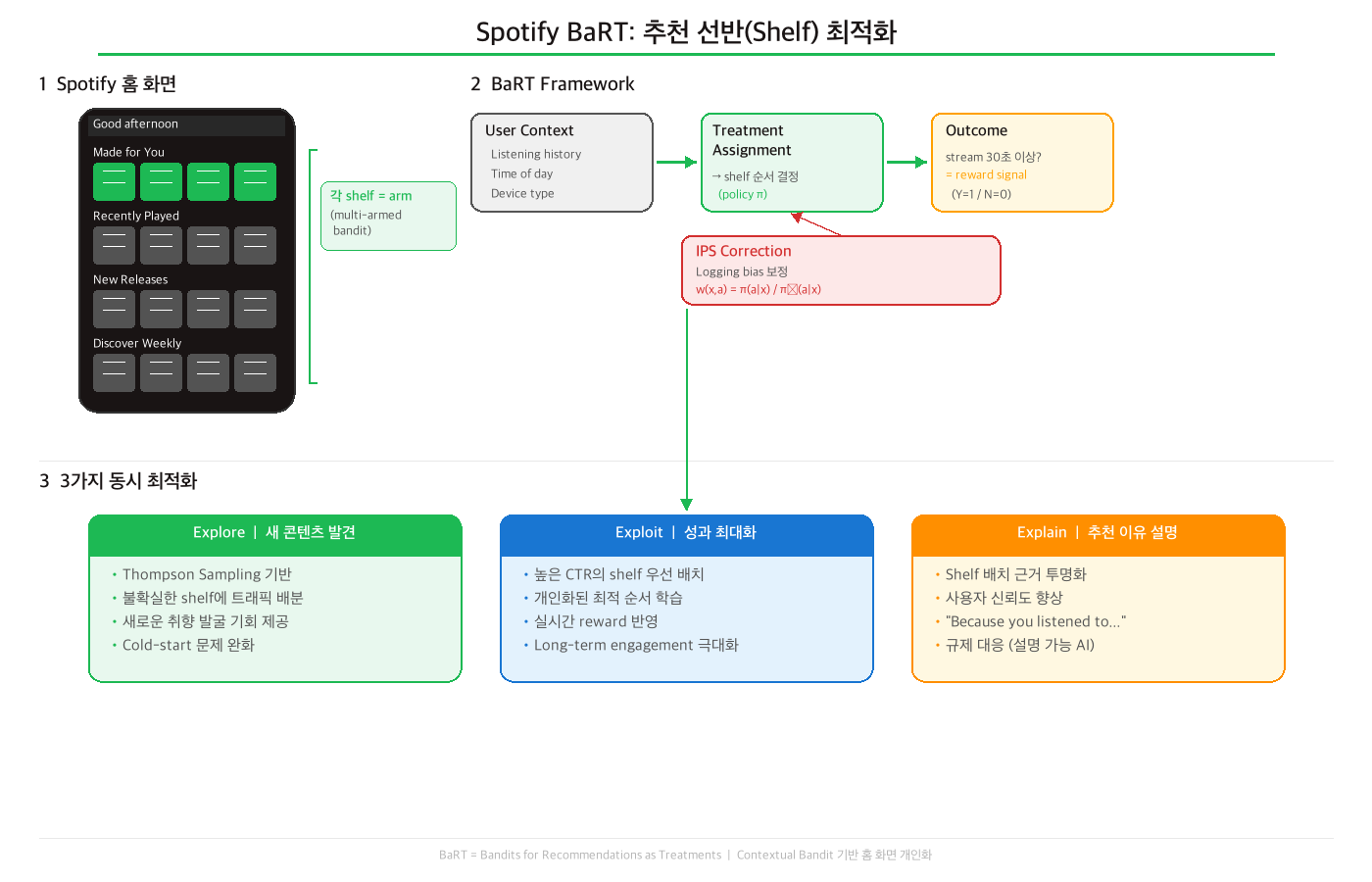
Spotify 앱을 열면 보이는 홈 화면을 생각해보자:
- 화면이 여러 개의 가로 선반(shelf)으로 구성된다
- 각 선반: "Made for You", "Recently Played", "New Releases", "Discover Weekly", ...
- 어떤 선반을 어떤 순서로 보여줄지가 추천 문제
- 각 선반 = arm, 선반의 순서 = arm 선택
단순히 "가장 많이 클릭되는 선반을 위에 놓자"로 끝나지 않는 이유:
- 유저마다 다르다: 어떤 유저는 새 음악을 발견하고 싶고, 어떤 유저는 익숙한 음악을 듣고 싶다
- 시간에 따라 변한다: 출근길에는 팟캐스트, 운동할 때는 업비트 음악
- 설명이 필요하다: "왜 이게 추천됐지?"를 유저가 이해할 수 있어야 한다
BaRT의 핵심 아이디어: Treatment Effect
BaRT는 추천을 의학의 임상시험처럼 바라본다:
| 의학 | 추천시스템 |
| 환자 (patient) | 유저 (user) |
| 처치 (treatment) — 약 A, 약 B, 위약 | 추천 (recommendation) — shelf A, shelf B, shelf C |
| 결과 (outcome) — 증상 개선 여부 | 결과 (outcome) — 30초 이상 재생 여부 |
| 처치 효과 (treatment effect) | 추천 효과 (recommendation effect) |
이 관점이 왜 유용하냐면, 인과추론(causal inference)의 도구를 쓸 수 있기 때문이다. 특히 편향된 로그 데이터를 보정하는 IPS(Inverse Propensity Score)를 사용할 수 있다.
IPS (Inverse Propensity Score) 보정
실무에서 가장 큰 문제: 과거 로그는 이전 추천 시스템이 만든 것이므로 편향되어 있다.
예를 들어, 이전 시스템이 "Made for You"를 80%의 유저에게 1번 선반에 놓았다면:
- "Made for You"의 클릭 데이터는 풍부하다
- "New Releases"의 클릭 데이터는 부족하다
- 단순히 과거 클릭률을 비교하면 편향된 결론을 내린다
IPS 보정:
$$\ hat{V}{\text{IPS}}(\pi) = \frac{1}{n} \sum{i=1}^{n} \frac{\pi(a_i | x_i)}{\pi_0(a_i | x_i)} \cdot r_i$$
- $\pi$: 평가하고 싶은 새 정책
- $\pi_0$: 과거 데이터를 수집한 정책 (logging policy)
- $\pi(a_i | x_i) / \pi_0(a_i | x_i)$: 중요도 가중치(importance weight)
- 직관: 과거 시스템이 잘 안 보여준 arm의 데이터에 더 큰 가중치를 부여하여 편향을 보정
비유: 설문조사에서 20대가 80%, 50대가 20%로 편향되었다면, 50대의 응답에 가중치를 더 줘서 전체 인구를 대표하도록 보정하는 것과 같은 원리다.
Explanation (설명) 생성
BaRT의 차별점은 추천과 함께 설명을 제공한다는 것이다:
- "당신이 좋아한 아리아나 그란데와 비슷한 아티스트" → 유저가 클릭 이유를 이해
- "지난주에 많이 들은 힙합 장르의 새 앨범" → 투명한 추천
- 설명이 있으면 유저 신뢰(trust)가 높아지고, 새로운 것도 시도하게 된다 (exploration 촉진)
설명은 arm의 일부다. 즉, "Made for You + 아리아나 그란데 설명"과 "Made for You + 힙합 설명"은 다른 arm이다.
실무 인사이트
1. Delayed Feedback:
- Spotify에서 "좋은 추천"의 기준: 30초 이상 재생. 클릭 직후에는 알 수 없다
- 해결: 클릭을 proxy reward로 사용하되, 최종 보상은 나중에 업데이트
2. Multiple Objectives:
- 클릭률만 높이면? → 자극적인 제목만 추천하게 된다 (clickbait)
- Spotify는 클릭률 + 재생 시간 + 다양성 + 설명 가능성을 동시에 최적화
- 실제로는 이 목표들을 가중합(weighted sum)으로 하나의 reward로 합친다
3. Batch Update:
- 실시간 업데이트는 시스템 부하가 크다. Spotify는 매일 배치로 모델을 재학습
- 이는 하루 동안 같은 정책으로 추천한다는 뜻 → 실시간 변화에 둔감
- trade-off: 시스템 안정성 vs 반응 속도
이 논문이 주는 핵심 교훈: 학계의 MAB 논문은 "regret을 최소화하라"만 말한다. 하지만 실제 서비스에서는 regret 최소화 외에도 설명 가능성, 다양성, 시스템 부하, delayed feedback 등 수많은 현실적 제약을 동시에 고려해야 한다. 이 갭을 이해하는 것이 실무 적용의 핵심이다.
읽기 가이드
- Section 1-2: 문제 정의와 motivation. Spotify 화면 예시가 직관적
- Section 3: BaRT 모델. treatment effect와 IPS가 핵심
- Section 4: explanation 생성 방법
- Section 5: 온라인 A/B 테스트 결과. 이론 논문에는 없는 실전 데이터!
- ACM 링크
논문 6: Open Bandit Dataset and Pipeline for Bandit Algorithms (Saito et al., NeurIPS 2021)
한 줄 요약: 실제 서비스(ZOZO)에서 여러 정책을 동시에 돌려서 수집한 bandit 로그를 공개하고, Off-Policy Evaluation을 위한 Python 파이프라인을 제공
Abstract 완전 해석
"Bandit algorithms have attracted widespread attention for their potential to improve many web-facing systems through efficient experimentation. Despite this, research has been hindered by the lack of large-scale, real-world logged bandit data."
→ Bandit 알고리즘은 효율적인 실험을 통해 웹 시스템을 개선할 잠재력으로 주목받았다. 하지만 대규모 실제 bandit 로그 데이터의 부재가 연구를 방해해왔다.
"To facilitate research, we propose the Open Bandit Dataset (OBD), a logged bandit dataset collected on a large-scale fashion e-commerce platform. The key feature of OBD is that it contains logged data collected by running multiple different bandit policies simultaneously, enabling the first realistic and reproducible benchmarking of off-policy evaluation (OPE)."
→ 연구를 촉진하기 위해 Open Bandit Dataset (OBD)을 제안한다. 대규모 패션 이커머스 플랫폼에서 수집된 bandit 로그다. OBD의 핵심 특징: 여러 다른 bandit 정책을 동시에 돌려서 수집했다. 이를 통해 off-policy evaluation의 현실적이고 재현 가능한 벤치마크를 최초로 제공한다.
"We also develop the Open Bandit Pipeline (OBP), a Python software for implementing and evaluating OPE estimators in a standardized manner."
→ Open Bandit Pipeline (OBP)이라는 Python 소프트웨어도 개발했다. OPE 추정량을 표준화된 방식으로 구현하고 평가할 수 있다.
왜 기존 데이터셋으로는 안 되는가?
MAB 연구의 가장 큰 문제: 대부분의 실험이 시뮬레이션이다.
| 데이터셋 | 문제점 |
| MovieLens, Netflix | 평점 데이터. Bandit 평가용으로 설계되지 않음. Action propensity를 모름 |
| Yahoo! (LinUCB 논문) | 공개 중단됨. 단일 정책으로 수집 → OPE 검증 불가 |
| 시뮬레이션 데이터 | 가정(선형 보상 등)이 맞으면 잘 되지만, 실제 환경의 복잡성을 반영하지 못함 |
| ZOZO OBD (이 논문) | 여러 정책 동시 수집 → OPE 추정값 vs 실제값 비교 가능! |
핵심 아이디어: 여러 정책 동시 운영
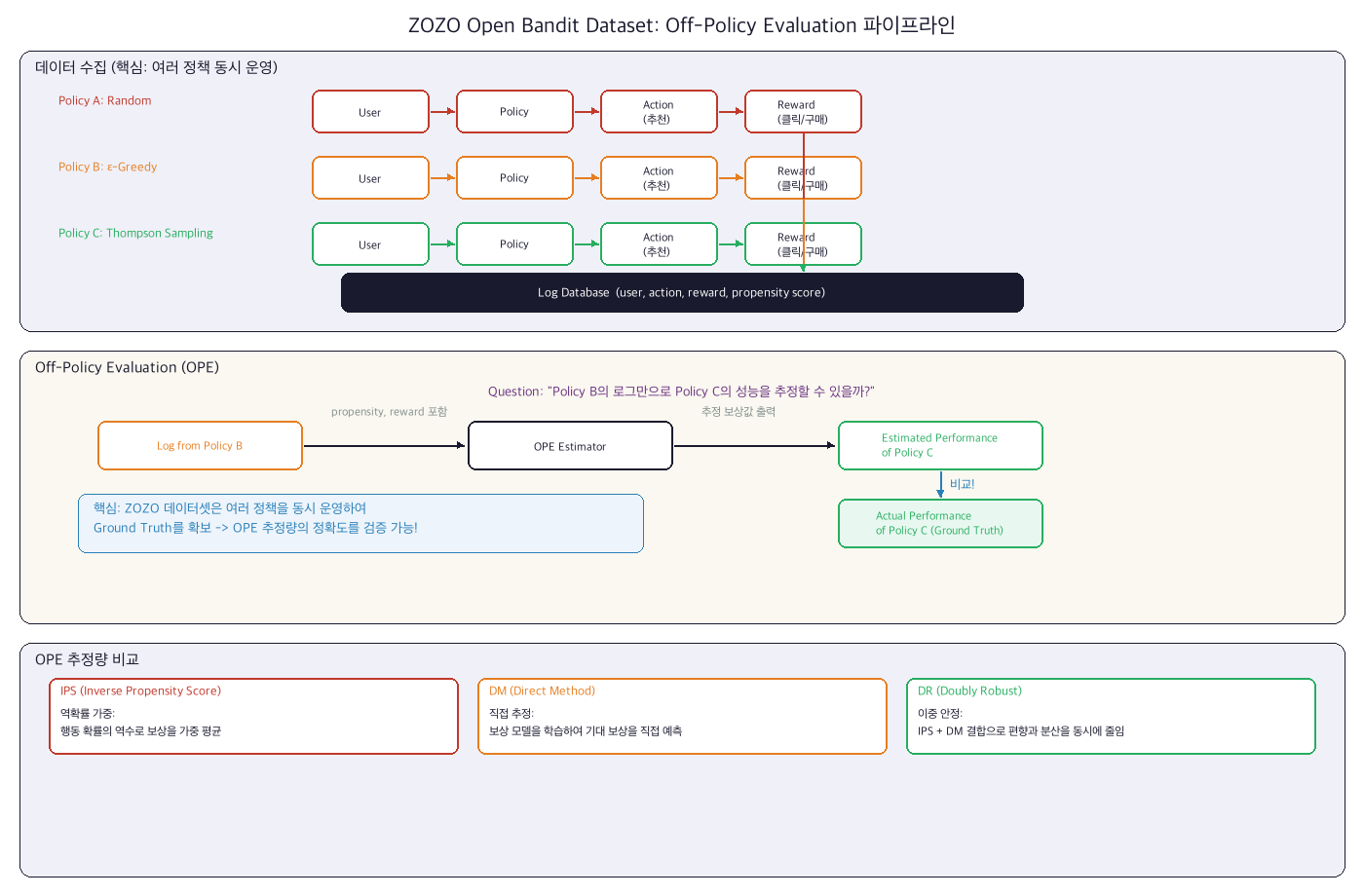
보통 A/B 테스트는 "정책 A vs 정책 B"를 비교한다. ZOZO는 한발 더 나아가 3가지 정책을 동시에 돌렸다:
- Policy 1: Bernoulli Thompson Sampling — 가장 정교한 정책
- Policy 2: Random — 완전 랜덤 추천 (uniform)
- Policy 3: ε-Greedy — ε=0.3으로 탐색
각 유저는 랜덤하게 3개 정책 중 하나에 배정되고, 해당 정책의 추천을 받는다. 모든 로그에 "어떤 정책이 추천했는지"가 기록된다.
왜 이게 핵심인가?
Random 정책의 로그를 가지고 Thompson Sampling의 성능을 "추정"할 수 있다 (OPE). 그리고 실제 Thompson Sampling 정책의 로그에서 "진짜 성능"을 알 수 있다. 추정값과 진짜값을 비교하면, OPE 추정량이 얼마나 정확한지 검증할 수 있다!
이것은 기존의 어떤 공개 데이터셋으로도 불가능했던 것이다.
데이터셋 상세
- 플랫폼: ZOZOTOWN — 일본 최대 패션 이커머스 (연 매출 약 1조원)
- 추천 위치: 상품 상세 페이지의 "이 상품과 함께 구매된 상품" 영역
- Action: 추천할 패션 아이템 (약 240개 후보)
- Reward: 클릭 여부 (binary)
- Context: 유저 피처 (성별, 나이, 지역 등) + 아이템 피처
- 규모: 약 2,600만 레코드 (12일간 수집)
- 각 레코드에 어떤 정책이 추천했는지와 propensity score가 포함
Off-Policy Evaluation (OPE): 핵심 개념
OPE의 핵심 질문: "새 정책을 실제로 배포하지 않고, 과거 로그만으로 성능을 추정할 수 있을까?"
이것이 실무에서 극히 중요한 이유:
- 새 알고리즘을 실서비스에 바로 배포하는 것은 위험하다 (매출 손실 가능)
- A/B 테스트는 시간과 비용이 많이 든다
- OPE로 "유망한 후보"를 미리 걸러내면, A/B 테스트 횟수를 줄일 수 있다
3가지 주요 OPE 추정량:
| 추정량 | 아이디어 | 장점 | 단점 |
| IPS (Inverse Propensity Scoring) | 보상에 중요도 가중치를 곱한다: $\frac{\pi(a|x)}{\pi_0(a|x)} \cdot r$ | Unbiased (편향 없음) | 분산(variance)이 매우 클 수 있다 |
| DM (Direct Method) | 보상 함수 $\hat{r}(x, a)$를 직접 학습하여 예측 | 분산이 작다 | 모델이 틀리면 편향(bias) 발생 |
| DR (Doubly Robust) | IPS + DM을 결합. $\hat{r}$로 baseline을 잡고, IPS로 잔차를 보정 | DM 또는 IPS 둘 중 하나만 맞아도 일관적(consistent) | 구현이 약간 복잡 |
Doubly Robust가 왜 "이중으로 견고"한가?
DR 추정량은 보상 모델($\hat{r}$)이 정확하면 일관적이고, propensity 모델($\pi_0$)이 정확해도 일관적이다. 둘 다 틀리면 편향이 생기지만, 둘 중 하나만 맞으면 OK다. 그래서 "doubly robust"라는 이름이 붙었다. 실무에서는 DR을 기본으로 쓰는 것이 권장된다.
Open Bandit Pipeline (OBP) 사용법
Python으로 바로 쓸 수 있다:
# pip install obp from obp.dataset import OpenBanditDataset from obp.ope import OffPolicyEvaluation, InverseProbabilityWeighting # 데이터 로딩 (자동 다운로드) dataset = OpenBanditDataset( behavior_policy="random", # Random 정책의 로그를 사용 campaign="all" ) bandit_feedback = dataset.obtain_batch_bandit_feedback() # OPE 실행 ope = OffPolicyEvaluation( bandit_feedback=bandit_feedback, ope_estimators=[InverseProbabilityWeighting()] ) # 새 정책의 action 확률 action_dist = new_policy.predict(bandit_feedback["context"]) estimated_value = ope.estimate_policy_values(action_dist=action_dist) print(estimated_value) # {"ipw": 0.0045}
실험 결과: OPE 추정량 비교
논문의 핵심 실험: Random 정책의 로그로 Thompson Sampling의 성능을 추정하고, 실제 TS 성능과 비교
| OPE 추정량 | 상대 오차 (낮을수록 좋음) | 평가 |
| IPS | \~15% | 분산이 크지만 편향은 작다 |
| DM | \~20% | 모델 오차로 인한 편향이 있다 |
| DR (Doubly Robust) | \~8% | 가장 정확. 실무에서 DR을 기본으로 쓰는 이유 |
| SNIPS (Self-Normalized IPS) | \~12% | IPS의 분산을 줄인 변형 |
읽기 가이드
- Section 1-2: 왜 이 데이터셋이 필요한지. 기존 데이터셋의 한계를 명확히 설명
- Section 3: OPE 프레임워크. IPS, DM, DR의 수학적 정의. 핵심 섹션
- Section 4: 데이터 수집 방법과 데이터셋 통계. "여러 정책 동시 수집"의 디테일
- Section 5: 실험 결과. OPE 추정량 비교가 Table 2에 정리되어 있다
- arXiv 링크 | GitHub (OBP)
직접 실험: 알고리즘 성능 비교
이론만으로는 감이 안 온다. 직접 실험해보자.
실험 설계
데이터셋: Open Bandit Dataset (ZOZO)
일본 최대 패션 이커머스 ZOZO(구 ZOZOTOWN)가 공개한 데이터셋이다. MAB off-policy 평가를 위해 설계된, 실제 서비스에서 수집된 유일한 공개 데이터다.
- 유저 약 1.2만 명
- 3가지 추천 정책(Bernoulli TS, Random, ε-greedy)으로 수집된 로그
- 각 로그에 action, reward, context 포함
- (GitHub: zr-obp | 논문)
비교 알고리즘:
- Random (baseline)
- Epsilon-Greedy (ε=0.1)
- UCB
- Thompson Sampling
- LinUCB (Contextual Bandit)
평가 지표: Cumulative Reward, Cumulative Regret
실험 결과
5개 arm(진짜 확률: 0.3, 0.4, 0.7, 0.2, 0.5)에 대해 5000 라운드를 100회 반복 실험했다.
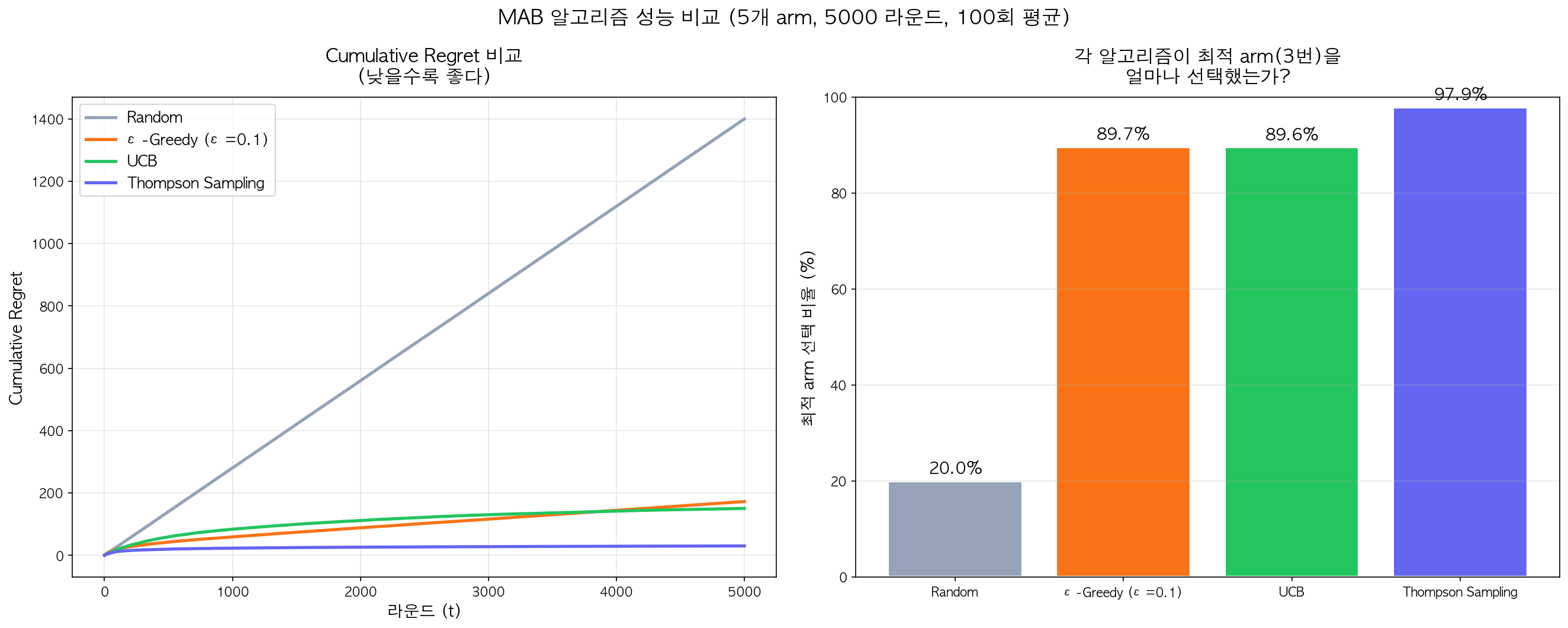
| 알고리즘 | Cumulative Regret | 최적 arm 선택 비율 | 해석 |
| Random | 1399.6 | 20.0% | 5개 중 1개 = 20%. 학습 없음 |
| ε-Greedy (ε=0.1) | 172.5 | 89.7% | 10%는 계속 랜덤 탐색 → regret이 선형 증가 |
| UCB | 150.4 | 89.6% | ε-Greedy보다 약간 나음. 불확실성 보너스가 체계적 |
| Thompson Sampling | 30.2 | 97.9% | 압도적. 빠르게 수렴하고 불필요한 탐색 최소화 |
핵심 관찰
- Thompson Sampling의 regret은 로그 스케일로 증가한다 — 라운드가 늘어나도 regret 증가가 거의 멈춘다
- ε-Greedy의 regret은 선형으로 증가한다 — 10%의 랜덤 탐색이 영원히 계속되기 때문
- UCB는 ε-Greedy보다 낫지만, Thompson Sampling에는 못 미친다
- 5000 라운드에서 Thompson Sampling의 regret(30.2)은 ε-Greedy(172.5)의 약 1/6에 불과하다
실험 코드
위 실험의 전체 코드다. 4개 알고리즘을 모두 구현하고 비교한다. Python + NumPy만으로 동작한다.
import numpy as np TRUE_PROBS = [0.3, 0.4, 0.7, 0.2, 0.5] K = len(TRUE_PROBS) T = 5000 BEST = max(TRUE_PROBS) # === 1. Random === def random_policy(t, counts, rewards): return np.random.randint(K) # === 2. Epsilon-Greedy === def epsilon_greedy(t, counts, rewards, eps=0.1): if np.random.random() < eps: return np.random.randint(K) q = np.where(counts > 0, rewards / counts, 0) return np.argmax(q) # === 3. UCB === def ucb(t, counts, rewards): if t < K: # 각 arm을 최소 한 번씩 return t q = rewards / counts bonus = np.sqrt(2 * np.log(t) / counts) return np.argmax(q + bonus) # === 4. Thompson Sampling === def thompson_sampling(t, alpha, beta_p): samples = [np.random.beta(alpha[i], beta_p[i]) for i in range(K)] return np.argmax(samples) # === 실험 실행 === def run(policy_fn, T): counts = np.zeros(K) rewards = np.zeros(K) alpha = np.ones(K) beta_p = np.ones(K) regrets = [] for t in range(T): if policy_fn == 'ts': arm = thompson_sampling(t, alpha, beta_p) elif policy_fn == 'ucb': arm = ucb(t, counts, rewards) elif policy_fn == 'eg': arm = epsilon_greedy(t, counts, rewards) else: arm = random_policy(t, counts, rewards) reward = 1 if np.random.random() < TRUE_PROBS[arm] else 0 counts[arm] += 1 rewards[arm] += reward if policy_fn == 'ts': if reward: alpha[arm] += 1 else: beta_p[arm] += 1 regrets.append(BEST - TRUE_PROBS[arm]) return np.cumsum(regrets), counts # 100회 반복 평균 for name, fn in [('Random','rand'), ('e-Greedy','eg'), ('UCB','ucb'), ('TS','ts')]: all_regrets = [run(fn, T)[0] for _ in range(100)] mean_regret = np.mean(all_regrets, axis=0) print(f'{name}: final regret = {mean_regret[-1]:.1f}')
정리
- Contextual Bandit은 유저 특성을 고려하여 개인화된 arm 선택이 가능하다
- 실무에서는 delayed reward, batch update, non-stationary 환경 등을 고려해야 한다
- 핵심 논문 6편을 순서대로 읽으면 이론→실무를 체계적으로 이해할 수 있다
- Open Bandit Dataset으로 직접 실험하여 알고리즘 성능을 비교할 수 있다